学习视频运动目标相关工作,寻找视频运动目标检测!!是c语言c语言程序c语言啊
学习视频运动目标相关工作
寻找视频运动目标检测!!它是C语言程序的C语言。机器视觉很难得到纯C代码建议:用C++版本代码编译一个so或dll,然后提供C接口。在的模块中再次调用

请问有哪些个人或公司熟悉设计此类软件:对视频图...
厦门美名软件有限公司(以下简称“美名”)位于厦门湖里后坑西盘石309号二楼,是高科技产业聚集的地方。它是一家新兴的高科技软件公司,集在线棋牌游戏、休闲游戏、手机游戏和音视频控制的研发于一体。 这并不坏,但最好的事情肯定是直接找到土坯。差异遮罩(Difference Matte)的差异遮罩的原理是拍摄没有主体/前景(只有背景)的单帧,并将视频与单帧进行比较。保留有差异的部分,去除无差异的部分,从而切除主体。这种方法适用于背景不纯或者甚至是非蓝色和绿色背景的视频的键控,但是它要求极高的视频质量,因为,函数cat _ mouse clear CLC mov = avi file(‘cat _ mouse . avi’);ts = 0:0.005:0.5;x0=[0,0];[t,x]=ode45(@cat_m,ts,x0);n =长度(x);图(1)绘图(0 (0,0,\' ...\')按住h1 =行(‘颜色’、‘0 01’、‘标记’,’)。,‘记号笔’,40,“伊拉塞莫,期待着,我也很关心这个问题。这应该很容易。
寻找视频运动目标检测!!是c语言c语言程序c语言啊
寻找视频运动目标检测!!它是C语言程序的C语言。机器视觉很难得到纯C代码建议:用C++版本代码编译一个so或dll,然后提供C接口。在的模块中再次调用
请问有哪些个人或公司熟悉设计此类软件:对视频图...
学习视频运动目标相关工作范文
本文的目录导航:
面向深度学习的目标检测和搜索算法研究??
[第一章]基于深度学习的视频运动目标介绍
[第二章]学习视频运动目标的相关工作
[第三章]基于卷积神经网络的视频目标定位与检测
[第四章]基于时间空双流的视频角色运动检测
[第五章]基于循环神经网络的视频目标自然语言搜索
[第6章]目标检测和搜索算法的结论和参考文献
第二章相关工作
第一章概述了研究的背景和意义、研究思路和创新点以及论文的结构。通过视频深度学习算法,完成视频中目标的检测和搜索。接下来,本章将从结构、原理以及在相应领域的应用等方面阐述与本文研究相关的视频图像目标检测和视频图像目标搜索算法,主要涉及视频预处理、图像识别、候选区域提取等算法。
2.1视频预处理
2.1.1镜头分割
镜头分割是处理视频图像问题的第一步。目前,成熟的镜头分割方法包括边缘比较法和块匹配法。
(1)边缘比较算法边缘比较算法杨明敏等人根据视频帧之间的变化动态地获取视频的关键帧[30】。首先,选择视频镜头的第一帧作为第一帧,并计算后续视频帧和关键帧之间的距离。如果某个视频帧和视频帧之间的距离超过某个阈值,则该帧是新的视频帧,并且重复它们之间的工作,直到视频拍摄结束。
它使用视频图像的边缘特征作为比较视频镜头之间差异的基础。切换视频镜头时,视频图像的边缘特征也会相应改变。
将阈值设置为T,基于第i+1个视频帧的边缘检测第i+1个视频帧的边缘减小的像素百分比dout,基于第I个视频帧的边缘检测第i+1个视频帧的边缘增大的像素百分比din,并且如下计算第I个帧和第I+1个帧之间的帧间差异:

在等式(2.1)中,如果帧间差值diff大于设定阈值t,则认为此时切换了视频的拍摄。
(2)块匹配算法块匹配算法关键帧提取的具体算法步骤如下:
它是将视频帧图像分成几个块,然后比较相应的连续帧块之间的相似性,得到镜头边界。
将视频帧图像分割成m个正方形,将小块之间的相似性比较阈值设置为T1,将视频帧之间的相似性小块的数量阈值设置为T2,并如下计算第1帧和第1+1帧的k个小块之间的相似性k1:
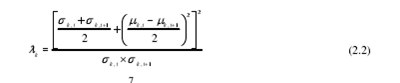
在公式(2.2)中,k,im和k,i1m+分别是第I视频帧图像和第i+1视频帧图像中的第k块的像素的加权平均值,并且k,is和k,i1s+分别是第I视频帧图像和第i+1视频帧图像中的第k块的像素的标准偏差。如果对应的两个块之间的相似度k1大于阈值T1,则这两个块被认为是不同的。
计算视频帧图像之间不同小块的数量n;如果n大于阈值T2,则表示视频镜头已经切换。
2.1.2关键帧提取
关键帧提取是视频图像预处理的第二步。关键帧,即最能反映视频镜头内容的视频帧图像,是将视频问题转化为图像问题的基础工作。
[28]
[29]
(1)初始化,将镜头的第一帧作为参考关键帧,用符号k=1表示;(2)计算后续视频帧与当前参考视频帧之间的距离,并分配k = k+1;(3)判断视频帧与当前参考关键帧之间的距离是否超过阈值,如果是,转到步骤(4),否则循环执行步骤(2);(4)选择第k帧作为关键帧,并将第k帧设置为当前参考帧;(5)判断是否有后续帧,如果有,循环执行步骤(2),否则结束。
2.1.3 RGB颜色通道提取
视频关键帧图像的RGB颜色通道提取是视频预处理的最后一步。图像的颜色通道是指图像中像素在相应通道上的颜色信息。
RGB颜色通道以红、绿和蓝三种颜色表示视频关键帧图像中像素的单独颜色值。本文将使用开放CV从视频帧图像中提取RGB彩色通道图像[31]。
2.2有线电视新闻网在视频图像识别中的应用
卷积神经网络是一种反向传播神经网络,可以通过传统的梯度下降法学习。训练后的神经网络能够有效提取图像特征,完成视频图像的识别。该神经网络不同于传统的逐层训练的神经网络,每一层的特征都是通过前一层特征的卷积核和局部区域的共享权值来计算的。由于这一特点,神经网络中权重参数的数量大大减少,避免了传统的神经网络[33]中的过拟合、局部优化和梯度扩散问题。此外,卷积神经网络对图像缩放和失真等变形不敏感,具有极高的鲁棒性。
2.2.1有线电视新闻网网络结构
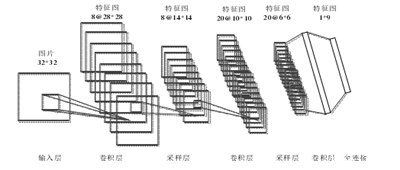
卷积神经网络模型的结构是多级结构。模型的每一级由多个二维特征图组成,每个二维特征图由多个神经元组成。典型的卷积神经网络结构,Le Net-5,如图2.1所示。它主要包括输入层、卷积层、采样层、全连接层和输出层。图像类别的概率在卷积神经网络的输入层和输出层输入。
卷积神经网络模型运算通常包括卷积运算、下采样运算和全连接。输入的原始图像相当于一个矩阵,它通过多个卷积核的运算产生一个特征层C1。对要素图层C1进行加权和偏置,以获得采样图层S2。然后通过相同的方法获得特征层C3、采样层S4和特征层C5。最后,要素图层C6被光栅化以获得完整的连接图层FC7来生成最终输出。
2.2.2有线电视新闻网的算法原理
上一节描述了有线电视新闻网的结构。本节从卷积、下采样和损失函数的角度详细描述了有线电视网络的算法原理。
卷积神经网络的输入层输入的初始图像被记录为映射,卷积神经网络的I层特征映射被记录为Fmapi,那么初始输入图像可以由Fmap0表示。第一层要素地图Fmapi的生成过程可以用公式(2.3)来描述:
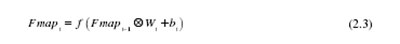
在2.3)中,Wi用符号表示第一层卷积核的权重向量?
表示卷积核和第一层特征映射Fmapi-1之间的卷积运算,bi表示偏置向量,最后通过非线性激活函数f(x)获得第一层特征映射Fmapi。为了减小特征图的维数并在某种程度上保持特征图比例恒定,通常需要在卷积计算之后对特征图执行下采样操作,如等式2.4所示:
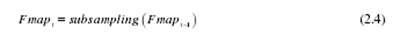
通过卷积神经网络中多个卷积层和采样层的循环运算,最终的特征映射被输入到全连接层中,然后基于输入的原始图像对全连接层的特征进行分类,得到各种类型的概率分布Y。
对于初始原始输入图像Fmap0,卷积神经网络多级运算得到的概率分布模型Y如公式(2.5)所示:
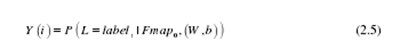
在公式(2.5)中,标签代表图像的第一个类别标签。
在神经网络的训练过程中,主要目标是最小化神经网络的损失函数值。常用的损失函数包括均方误差(均方误差)函数和负对数似然(负对数似然)函数等。,如公式(2.6)和(2.7)所示:
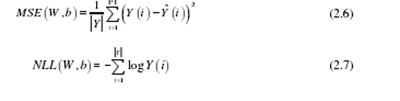
2.3目标候选区域提取算法
候选区域提取算法用于提取视频图像中目标的可能区域。候选区域的提取是视频图像目标检测的基础工作。本节将介绍三种常用的目标候选提取算法:
滑动窗口算法,选择性搜索算法[34]和边缘盒算法[35]。
2.3.1滑动窗口算法
滑动窗口是目标候选区域最基本的生成算法。该算法通过遍历视频图像中的每个像素,以像素为目标矩形区域的起点,构造不同尺寸的矩形窗口。
由于该算法列举了视频图像中所有目标候选区域的可能位置,虽然该方法能够生成准确的目标位置,但也生成了大量冗余的目标候选区域。
2.3.2选择性搜索算法
选择性搜索算法是一种目标区域推荐算法。该算法将视频图像分成多个子区域,计算相邻子区域之间的相似度,并合并相似度最大的图像子区域。通过不断合并子区域,最终获得少量高召回率的目标候选区域。在该方法中,通过融合包括颜色、纹理和尺寸在内的各种特征的相似性来获得子区域之间的相似性。具体的选择性搜索算法包括以下四个步骤:
(1)将视频图像分成多个子区域,其中子区域被设置为{}1 2、、、nR = r r r(2)计算所有相邻视频图像子区域之间的相似度(,)m ns r r,相似度集为{( )},m nS = s r r(3)对于两个相邻的视频图像子区域(,)m nr,将相似性集合S中的最大相似性max(S)合并到新的子区域中。将r、newr添加到子区域集合r中,并且在相似性集合S中,删除最初与区域mr和区域nr相关的相似性,并且计算newr和其他区域之间的相似性并将其添加到相似性集合S中..(4)重复步骤(3),直到相似性集合S为空集合,其中子区域集合R中的子集是视频图像中目标的分割区域,与分割区域对应的外接矩形是视频图像中候选目标区域对应的边界框。
2.3.3边盒算法边盒
(Edge Box)算法是根据视频图像的边缘信息确定目标区域的算法。首先获取视频图像的边缘信息,然后获取边缘轮廓分组,并计算边缘分组之间的相似度。然后,使用边缘轮廓分组之间的相似性来计算每个边缘轮廓的权重值。通过权重值确定边缘轮廓分组是否属于目标轮廓的一部分。具体算法流程如下:
(1)计算输入图像的边缘信息,得到边缘图像,并利用非最大压缩NMS去除边缘图像中过多的紧密边缘;(2)在边缘图上继续搜索连接的边缘点,直到两个边缘点之间的方向角差值之和大于p2,得到边缘点分组{}1 2、、、nS S(3)计算边缘点组之间的相似度a(i,j),得到相似度集{( )}a i,j;(4)通过相似度集计算每个分组的权重(|)iWα。权重为1表示边缘点被分组在目标区域的轮廓内,权重为0表示边缘点被分组在目标区域的轮廓之上或之外。最后,通过每个边缘点分组得到目标区域的位置边界。
2.4 RNN在基于文本的目标搜索中的应用
卷积神经网络对图像处理有很好的效果,但不适用于文本处理。循环卷积神经网络(RNN)是一种用于处理序列数据的神经网络[36]。本文将用于处理目标的自然语言搜索。将分别描述RNN的网络结构、RNN的工作原理和RNN的GRU网络[的特殊类型。
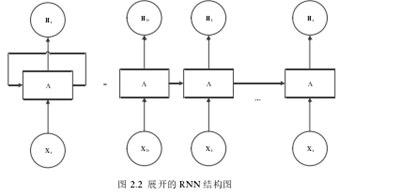
2 . 4 . 1 RNN网络结构循环神经网络的结构图
如图2.2所示,等号左侧表示传统循环神经网络的结构,等号右侧表示循环神经网络在时间序列中的发展。循环神经网络的结构包括输入层、隐藏层和输出层三部分,其中隐藏层包含具有反馈机制的神经元,可以循环地将输出信息输入到下一个模块,实现上下文信息的传输,这就是循环神经网络能够处理文本序列的原因。
2 . 4 . 2 RNN算法原理
循环神经网络常用于文本处理。本节将解释处理文本{} 12、、、nww时t时刻循环神经网络的工作原理。如图2.3所示,整个网络的输入为tx,输出为ty,隐藏层的状态用th表示。输入层的输入向量tx由两部分组成,即前一层的字向量tw和隐藏状态t1h。输入层的输入矢量tx的计算公式如(2.8)所示:

循环神经网络的隐层用于处理输入向量tx,输出层用于输出对应于时间t的输出结果ty,隐层生成的时间t的隐状态th和输出层的输出ty的计算公式如下(2.9)和(2.10)


2.4.3 GRU神经网络
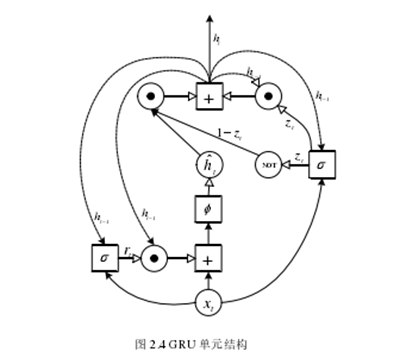
GRU网络是RNN神经网络的一种。GRU神经网络类似于LSTM的长短期记忆(Long Short Memory),它使用门周期单元来控制隐藏节点的输出,能够有效地模拟时间序列的变化。然而,GRU网络比LSTM网络更简单、更容易实现,并且只包括两个门结构:更新门和复位门。本文将利用GRU网络处理视频图像目标的自然语言搜索问题。
图2.4示出了时间t的GRU单元的具体结构,其中tx表示当前时间的输入,虚线表示前一时间输出的隐藏状态t1h-,实现了这条线上的计算过程包括权重,并且这表示当前时间输出的GRU隐藏层的状态。这表示当前时间隐藏层的隐藏状态的候选值,tr表示GRU单元的复位门,tz表示GRU单元的更新门。GRU机组的工作过程可以用以下公式表示:
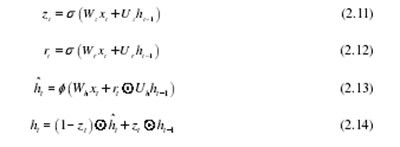
其中s代表sigmoid函数,f代表tanh函数,代表Hadamard乘积,w和u代表GRU单位需要训练的权重参数矩阵。当复位门tr接近0时,忽略前一隐藏层的信息,仅将当前时间的输入作为输入,使得GRU单元能够丢弃自然语言搜索语句中不相关的信息;更新门tz用于指示先前隐藏状态进入当前隐藏状态th的量。每个GRU单元可以在不同的时间范围内学习。当复位门tr激活时,GRU单元可以在短距离内学习依赖性,而当更新门tz激活时,它可以在长距离内学习依赖性。
2.5本章摘要[/s2/]
本章主要总结了本文中涉及视频目标检测和搜索研究的几种挖掘算法,包括视频场景预处理算法、卷积神经网络在图像识别中的应用、目标候选区域提取算法和循环神经网络。在本章中,我们首先提取视频的关键帧,并将视频问题转化为图像问题。然后分析了有线电视新闻网的结构和原理,并以有线电视新闻网为图像特征提取模型。为了检测和分析目标在视频帧图像中的位置,我们分析了三种视频目标候选区域算法。最后,考虑到有线电视新闻网和文本处理的不适用性,提出了循环神经网络的结构和原理,并利用循环神经网络处理自然语言搜索语句。上述工作将为以下三个研究点的进一步研究铺平道路。
学习视频运动目标相关工作


