代写数据结构课程设计(价格+渠道分析),数据结构C语言版编程主题找一起写10篇,有人做吗
代写数据结构课程设计(价格+渠道分析)
数据结构c语言版编程主题找一起写10篇,有人做吗?如图源代码:/*小l住在有许多城市的地方,作者:q8392192192192286算法认为:城市图采用DFS搜索,搜索终止条件是:到达终点或Vmax-Vmin > dV设置dV=Vmax-Vmin,寻找dV的方法是使用Vmax,Vmin的递归历史图结构采用“邻接表”方法,存储结构采用数组。*//
数据结构C语言版编程题目找代写5块一道,有人做吗
头儿,恐怕30岁以下的人都不会回答你的问题。
数据结构C语言版编程主题找一起写10篇,有人做吗
数据结构c语言版编程主题找一起写10篇,有人做吗?如图源代码:/*小l住在有许多城市的地方,作者:q8392192192192286算法认为:城市图采用DFS搜索,搜索终止条件是:到达终点或Vmax-Vmin > dV设置dV=Vmax-Vmin,寻找dV的方法是使用Vmax,Vmin的递归历史图结构采用“邻接表”方法,存储结构采用数组。*//
数据结构C语言版编程题目找代写5块一道,有人做吗
代写数据结构课程设计(价格+渠道分析)范文
课程设计是专业理论与实践相结合的重要过程。它主要是指教师安排学生在学习专业课程后的一段时间内,有组织地或分散地完成一些任务。课程设计一般从一周到一个月或更长,主要包括自己的作品和设计报告。由于数据结构课程设计困难,一些学生没有足够的时间完成课程设计。这时,你可以找一个写作机构来完成。本文主要介绍写作数据结构课程设计的相关问题。
一、数据结构课程设计写作价格
论文等级论文字数价格/千字专科3000字~4000字150元~180元本科5000字~6000字200元~240元研究生7000字~9000字260元~300元博士9000字~10000字300元~340元
代表作者影响数据结构课程设计价格的因素有几个:
1。少校。不同的专业价格绝对不同。科学中的平面设计肯定比文科更贵。
2。教育背景。专业课程和本科课程没有太大区别。硕士和博士课程的论文肯定更难,价格也相对较高。
3。时间要求。如果正常情况下课程设计需要一周时间,而你需要三天时间来完成,那么写作的人将会加班,而且肯定会收取额外的紧急费用。

二。数据结构课程设计最新写作渠道分析
(1)代理写作的渠道有哪些?
1。百度写作代理。
(1)组织特点:相关备案信息,服务团队齐全,实力雄厚,运行时间长。
(2)作者的特点:专业的公司管理,丰富的写作经验,有保证的论文质量和系统的服务流程。
(3)售后服务特点:特殊服务、免费修订、免费查重、高保密系数、提供查重测试报告。
(4)价格特征:高性价比。
2,个人写作。
(1)写作代表的特点:写作周期长,主要是兼职。
(2)作者的特点:写作经验不足,完成效率低。
(3)售后特点:售后不及时,无重复检验报告,个人信息保密有问题。
(4)价格特征:价格不明确。
3,淘宝写作店。
(1)店铺特征:大部分是中介机构写的,可信度低。
(2)作者的特点:专业水平低,写作经验不足,售后服务不完善。
(3)售后服务特点:一对一服务。
(4)价格特征:较高的收费和商店之间的巨大价格差异。
(二)[可靠写作机构的特点/s2/]
1。写网站需要很长时间。
代理网站的长期运行肯定会花费大量的金钱和时间。一般来说,这样的网站更正式。
2,网站布局和网站内容。
普通网站拥有专业的网站运营商,布局良好,可读性可靠。
3,网站联系信息和客户服务专业知识。
正式的写作机构通常提供多种联系方式(如QQ、电话和电子邮件),以方便客户联系和沟通,并及时解决客户遇到的问题。
4。代理商的价格是合理的。
正式机构提供的论文是专业的,需要由专业教师完成。根据专业类别、字数、查重率、时间等因素,价格是合理的。120元就能完成一篇论文的现象肯定不会发生。
5。完成论文写作过程和退款过程。
6。提供修订和重复检查率,或最终确定测试报告。
本月之前需要客户的测试报告。如果其他客户没有测试报告,他们可能是通过阅读清单获得信用的骗子。
7。写论文的时间长度。
写作有一个很长的周期,至少一个月。本文要经过许多程序,如编写、修改、检查和修改查重率。因此,通常是装配线工作可以在短时间内完成,这很容易导致与他人的重复。
三。数据结构课程设计写作过程分析
(1)双方应协商具体的书面事宜,并代表双方写报价。
(2)客户同意报价并签署代理协议。
(3)客户支付部分定金,并安排作者代表他创作作品。
(4)作者完成创作后,将部分内容提交给客户审阅。
(5)客户对审计满意后,应支付余额。
(6)代表客户书写并发送全文,并开始免费售后服务。
4。合格的数据结构课程设计有哪些特点?
(1)高创意。
所有的课程设计都离不开原创性这一基本问题。没有创意,数据库课程设计就没有价值。这是最基本的。
(2)带视图的页面。
这是菜单,它是数据结构的基础。有几个菜单,几个基本的观点,他们扮演什么角色,角色的基本比例和结构都应该清楚。
(3)有一个坐标系。
为了体现向量(向量的加减点乘以叉积)、光照法线贴图、内存管理和图形优化的概念,为了理解世界坐标和局部坐标之间的关系,必须有可移动和旋转的代码。
(4)理论与实践的有机结合。
虽然数据结构课程设计要求学生有较高的实践操作能力,但理论知识不能放松。没有以科学理论为指导的课程设计,它无法经受住审查。
写作数据结构课程设计的相关问题在这里为大家分析。我希望每个人都能仔细阅读写作价格和渠道。毕竟,这直接影响到每个人的利益。
扩展阅读:八种数据结构分类
数据结构指的是一组数据元素,它们之间有一种或多种关系,以及该组数据元素之间的关系。
常见的数据结构包括:数组、堆栈、链表、队列、树、图、堆、哈希表等。,如图所示:
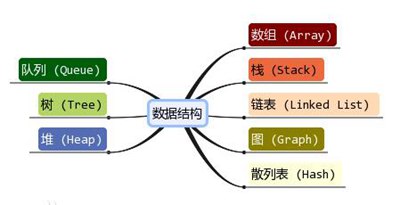
每个数据结构都有自己独特的数据存储方法。以下是对它们的结构、优点和缺点的介绍。
1,阵列
数组是可以再内存中连续存储多个元素的结构,在内存中的分配也是连续的,数组中的元素通过数组下标进行访问,数组下标从0开始。例如下面这段代码就是将数组的第一个元素赋值为 1。 数组是一种结构,其中多个元素可以连续存储在内存中,并且在内存中的分配也是连续的。数组中的元素通过数组下标访问,下标从0开始。例如,下面的代码将数组的第一个元素求值为1。
数组是一种结构,其中多个元素可以连续存储在内存中,并且在内存中的分配也是连续的。数组中的元素通过数组下标访问,下标从0开始。例如,下面的代码将数组的第一个元素求值为1。
优势:
1、根据索引快速查询元素
2.根据索引遍历数组很方便。
劣势:
1.阵列大小固定后,就无法扩展
2.数组只能存储一种类型的数据
3.添加和删除操作很慢,因为需要移动其他元素。
适用情景:
查询频繁,对存储空的要求很低,添加和删除很少。
2,堆栈
堆栈是一种特殊的线性表,只能在线性表的一端操作。允许在堆栈顶部操作,但不允许在堆栈底部操作。堆栈的特征是:先入先出,或最后入先出。从堆栈顶部放入元素的操作称为堆栈入口,取出元素的操作称为堆栈出口。
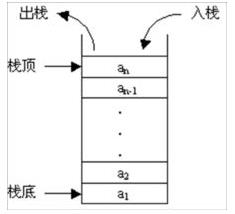
堆栈的结构就像一个容器,先放进去的东西可以稍后取出。因此,堆栈通常应用于实现递归函数的场景,例如斐波那契序列。
3,排队
队列像堆栈一样,也是一个线性表。不同之处在于队列可以在一端添加元素,在另一端获取元素,即先入先出。从一端放入元素的操作称为入队,取出元素称为出队。示例图如下:
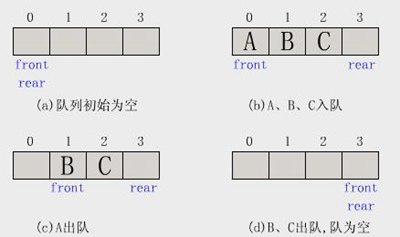
使用场景:由于队列的先进先出特性,非常适合多线程阻塞队列管理。
4,链接列表
链表是物理存储单元上不连续和不连续的存储结构。数据元素的逻辑顺序通过链表的指针地址来实现。每个元素包含两个节点,一个是存储元素的数据字段(memory /[/k0/),另一个是指向下一个节点地址的指针字段。根据指针的方向,链表可以形成不同的结构,如单链表、双链表、循环链表等。
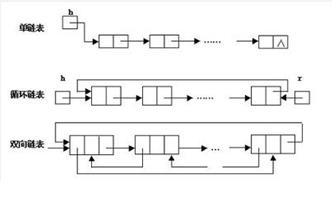
优势:
链表是一种常见的数据结构。它不需要初始化容量,可以任意增加或减少元素。
添加或删除元素时,只需更改前后元素节点的指针字段来指向地址,所以添加和删除都很快;
劣势:
因为它包含大量指针字段,所以它在空之间占据很大空间;
查找元素需要遍历链表,这非常耗时。
适用情景:
数据量很小,需要频繁增加和删除场景
5,树
树是一种数据结构,它是一组具有层次关系的n(n>=1)个有限节点。它被称为“树”,因为它看起来像一棵倒置的树,也就是说,它的根向上,叶子向下。它具有以下特点:
每个节点都有零个或多个子节点;
没有父节点的节点称为根节点;
每个非根节点都有并且只有一个父节点;
除了根节点之外,每个子节点可以分成几个不相交的子树。
在日常应用中,我们讨论并使用更多的树结构,即二叉树。
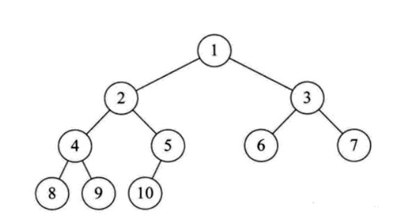
二叉树是一种特殊的树,具有以下特征:
1.每个节点最多有两个子树,节点的度数最多为2。
2.左子树和右子树是有序的,顺序不能颠倒。
3.即使一个节点只有一个子树,也应该区分左右子树。
二叉树是一个有用的折衷。它可以快速添加和删除元素,并且在搜索中有许多算法优化。因此,二叉树兼有链表和数组的优点。这是两者的优化方案,在处理大量动态数据时非常有用。
分机:
二叉树有许多扩展的数据结构,包括平衡二叉树、红黑树、B+树等。这些数据结构基于二叉树导出许多函数,并在实际应用中得到广泛应用。例如,mysql在其数据库索引结构中使用B+树,HashMap在其底层源代码中使用红黑树。这些二叉树具有强大的功能,但它们的算法相对复杂。如果你想学习,你仍然需要时间去深入。
6,散列表
哈希表,也称为哈希表,是根据键码和值直接访问的数据结构。哈希表通过键和值映射到集合中的一个位置,以便可以快速找到集合中相应的元素。
记录存储位置=f(键)
这里的对应关系f成为哈希函数,也称为哈希函数,哈希表是通过固定的算法函数,即所谓的哈希函数(hash function),将Key转换成整数。然后,该数字用于取数组长度的剩余部分,剩余部分的结果作为数组的下标。值存储在数组空中,下标为数字。这个存储器空可以充分利用数组的搜索优势来查找元素,所以搜索速度非常快。
哈希表在应用程序中也很常见。例如,Java中的一些集合类是通过利用哈希原理构建的,比如哈希表(HashMap)、哈希表(HashTable)等。利用哈希表的优势,在集合中查找元素非常方便。但是,因为散列表基于从数组派生的数据结构,并且添加和删除元素相对较慢,所以经常需要使用数组链表,即拉链方法。拉链方法是一种将数组和链表相结合的结构。hashMap底层的存储更早使用了这种结构,直到jdk1.8数组和红黑树的结构才被替换。示例图如下:
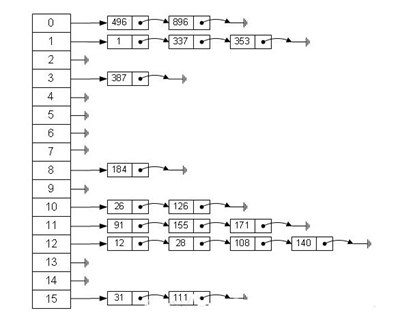
从图中可以看出,左边显然有一个数组。数组的每个成员都包括一个指向链表头的指针。当然,这个链表可以是空,也可以有许多元素。我们根据元素的一些特性将元素分配给不同的链表,并且根据这些特性找到正确的链表,然后从链表中找到这个元素。
哈希表有许多应用场景,当然,也有许多问题需要考虑,例如哈希冲突。如果处理不好,会浪费很多时间,导致应用程序崩溃。
7,堆
堆是一种特殊的数据结构,它可以被视为树的数组对象,并具有以下属性:
堆中节点的值总是不大于或小于其父节点的值;
堆总是一个完整的二叉树。
根节点最大的堆称为最大堆或大根堆,根节点最小的堆称为最小堆或小根堆。常见堆包括二进制堆、斐波那契堆等。
堆定义如下:n个元素{k1,k2,ki,...,kn}被称为堆,如果且仅当满足以下关系时。
(ki = k2i,ki > = k2i+1),(I = 1,2,3,4...n/2),满足前者的表达式是小的顶部堆,而满足后者的表达式是大的顶部堆。两者的结构图可以排列成完整的二叉树。示例图如下:
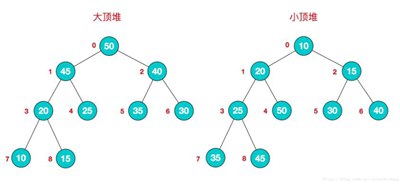
由于堆的有序性,它们通常用于对数组进行排序,这被称为堆排序。
8,图[/s2/]
图由一组有限的节点和一组边组成。其中,为了区别于树结构,图结构中的节点通常称为顶点,边是有序的顶点对。如果两个顶点之间有一条边,这意味着这两个顶点有相邻关系。
根据顶点指向的方向,它可以分为无向图和有向图:
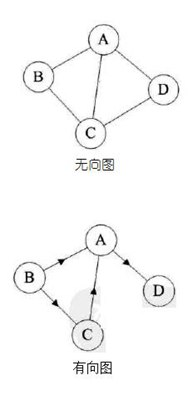
图是一个相对复杂的数据结构。它有一个相对复杂和高效的数据存储算法。它具有邻接矩阵、邻接表、交叉链表、邻接多表、边集数组等存储结构。这里没有扩展。读者对自己深入学习感兴趣。


