寻找异常数据的几个人工智能方法对比,我想问什么建筑和人工智能(计算机/程序设计...
寻找异常数据的几个人工智能方法对比
我想问一下哪些建筑和人工智能(计算机/程序设计...我记得主要做3d绘图和autocad等。现在预算全部由电脑控制,将电脑和建筑结合在一起。至于gps定位和计算机在建筑中的应用,也有很多,但是应该没有特别的专业,或者应该很少,然后还有所谓的智能建筑、无线城市等。也是建筑商。
海尔冰箱在人工智能状态下温度异常
亲,如果产品使用中有任何问题,可以打电话给客服,联系售后人员进行现场维护和处理。
我想问什么建筑和人工智能(计算机/程序设计...
我想问一下哪些建筑和人工智能(计算机/程序设计...我记得主要做3d绘图和autocad等。现在预算全部由电脑控制,将电脑和建筑结合在一起。至于gps定位和计算机在建筑中的应用,也有很多,但是应该没有特别的专业,或者应该很少,然后还有所谓的智能建筑、无线城市等。也是建筑商。
海尔冰箱在人工智能状态下温度异常
寻找异常数据的几个人工智能方法对比范文

介绍
异常数据检测的人工智能方法有很多,如传统的基于统计的方法、基于距离的方法、基于密度的方法、基于聚类的方法等。然而,这种传统的异常数据检测方法仍然存在一些缺陷和不足。基于统计的数据检测方法要求预先知道检测数据的分布。在基于距离的方法中,距离函数和参数的选择存在很大困难,基于密度的数据检测方法具有很高的时间复杂度。这些问题极大地限制了异常数据挖掘算法在现实中的应用。本文重点介绍了人工智能在异常数据挖掘中的应用历史,并对其优缺点进行了分析和比较。
异常数据挖掘中常用的几种人工智能方法分析
2.1神经网络方法
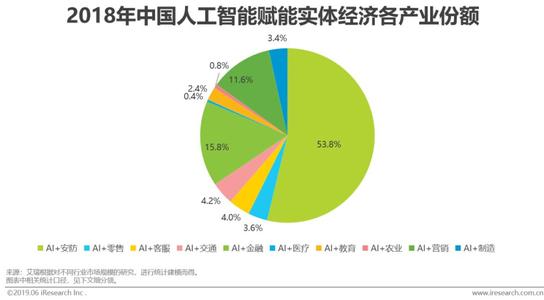
神经网络模型主要由三层组成,包括输入层、隐藏层和输出层。第一层是输入层,输入层的节点代表多个预测变量,输出层的节点代表多个目标变量,隐藏层位于输入层和输出层之间。神经网络模型的复杂性取决于隐藏层的层数和节点数。每层允许有多个节点。神经网络模型主要用于解决回归和分类问题。其结构图如下图所示。
 从上图可得,节点 X1,X2,X3作为神经元的输入,代表多个预测变量,它可以是来自神经网络的信息,也可以是另一个神经元的输出;W1,W2, ,Wn是神经元的权值,表示各个神经元的连接强度。通过神经网络模型的结构图可知,该方法的实现过程:首先将每个训练样本的各属性取值同时赋给第 1 层即输入层;各属性值再结合各自的权重赋给第 2 层(隐含层的第 1 层),第 1 层隐含层再结合各自的权重输出又作为下一隐含层的输入,最后一层的隐含层节点带权输出赋给输出层单元,输出层最终给出各个训练样本的预测输出。从上图中,节点X1、X2、X3是神经元的输入,并代表多个预测变量,这些预测变量可以是来自神经网络的信息或另一个神经元的输出。W1、W2、Wn是神经元的权重,代表每个神经元的连接强度。根据神经网络模型的结构图,该方法的实现过程如下:首先,将每个训练样本的每个属性值同时分配给第一层,即输入层;每个属性值结合它们各自的权重被分配给第二层(隐藏层的第一层),并且第一层的隐藏层结合它们各自的权重输出被用作下一隐藏层的输入。最后一层的隐藏层节点被分配给具有加权输出的输出层单元,并且输出层最终给出每个训练样本的预测输出。
从上图可得,节点 X1,X2,X3作为神经元的输入,代表多个预测变量,它可以是来自神经网络的信息,也可以是另一个神经元的输出;W1,W2, ,Wn是神经元的权值,表示各个神经元的连接强度。通过神经网络模型的结构图可知,该方法的实现过程:首先将每个训练样本的各属性取值同时赋给第 1 层即输入层;各属性值再结合各自的权重赋给第 2 层(隐含层的第 1 层),第 1 层隐含层再结合各自的权重输出又作为下一隐含层的输入,最后一层的隐含层节点带权输出赋给输出层单元,输出层最终给出各个训练样本的预测输出。从上图中,节点X1、X2、X3是神经元的输入,并代表多个预测变量,这些预测变量可以是来自神经网络的信息或另一个神经元的输出。W1、W2、Wn是神经元的权重,代表每个神经元的连接强度。根据神经网络模型的结构图,该方法的实现过程如下:首先,将每个训练样本的每个属性值同时分配给第一层,即输入层;每个属性值结合它们各自的权重被分配给第二层(隐藏层的第一层),并且第一层的隐藏层结合它们各自的权重输出被用作下一隐藏层的输入。最后一层的隐藏层节点被分配给具有加权输出的输出层单元,并且输出层最终给出每个训练样本的预测输出。
2.2蚁群聚类算法
聚类是数据挖掘中一个活跃的研究领域,涉及面广。许多计算机学者提出了一系列通过模仿生物行为来解决问题的新方法。蚂蚁搜索模式样本所属聚类中心的概率计算公式如公式(1)所示。
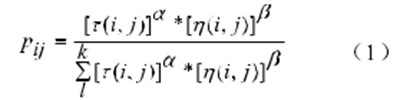 其中,α,β 为参数,初始聚类中心为随机选取的 k 个模式样本点。τ(i,j) 为样本 Xj到聚类中心 mj之问的信息素 i=1,2, ,n,j=1,2,,k ;η(i,j) 为启发函数,其表达式如式(2)所示。其中,α和β为参数,初始聚类中心随机选取K个模式样本点。τ(i,j)是样本Xj和聚类中心mj之间的信息素I = 1,2,n,j = 1,2,k;η(i,j)是启发式函数,其表达式如公式(2)所示。
其中,α,β 为参数,初始聚类中心为随机选取的 k 个模式样本点。τ(i,j) 为样本 Xj到聚类中心 mj之问的信息素 i=1,2, ,n,j=1,2,,k ;η(i,j) 为启发函数,其表达式如式(2)所示。其中,α和β为参数,初始聚类中心随机选取K个模式样本点。τ(i,j)是样本Xj和聚类中心mj之间的信息素I = 1,2,n,j = 1,2,k;η(i,j)是启发式函数,其表达式如公式(2)所示。
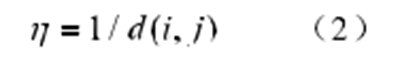 其中,dj为模式样本 Xj到聚类中心 mj的欧氏距离为 (i=1,2, ,n,j=1,2, ,k)。蚂蚁搜索整个模式样本空间,形成一个聚类结果后,聚类中心 mj各分量的值为该类 Cj中模式样本各属性的均值,计算公式如(3)。其中dj是从模式样本Xj到聚类中心mj的欧几里德距离(I = 1,2,n,j = 1,2,k)。蚂蚁搜索整个模式样本空形成聚类结果后,聚类中心mj的每个分量的值就是该类Cj中模式样本的每个属性的平均值,计算公式如(3)所示。
其中,dj为模式样本 Xj到聚类中心 mj的欧氏距离为 (i=1,2, ,n,j=1,2, ,k)。蚂蚁搜索整个模式样本空间,形成一个聚类结果后,聚类中心 mj各分量的值为该类 Cj中模式样本各属性的均值,计算公式如(3)。其中dj是从模式样本Xj到聚类中心mj的欧几里德距离(I = 1,2,n,j = 1,2,k)。蚂蚁搜索整个模式样本空形成聚类结果后,聚类中心mj的每个分量的值就是该类Cj中模式样本的每个属性的平均值,计算公式如(3)所示。
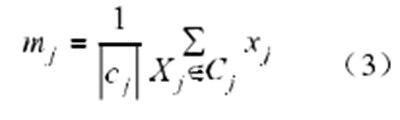 2.3 基于知识粒度的异常数据挖掘算法2.3基于知识粒度的异常数据挖掘算法
2.3 基于知识粒度的异常数据挖掘算法2.3基于知识粒度的异常数据挖掘算法
粒度计算是人工智能领域一个新发展的研究方向。这种方法处理不确定信息。它主要包括三个模型,即粗糙集模型、模糊集模型和商空模型。该方法的基本思想是使用不同粒度的信息来解决问题。该理论已被广泛应用于许多领域,如数据挖掘、决策支持与分析、机器学习等。知识粒度为异常数据挖掘处理不确定数据提供了新的解决方案。一种基于知识粒度的异常数据挖掘算法,它不需要预先知道数据的分布,在用知识粒度测量各种对象之间的距离和异常程度时,可以有效地挖掘异常数据。
3方法比较
通过对上述方法的分析,每种方法都有自己的优缺点。基于聚类的数据挖掘方法侧重于聚类问题,极大地限制了该算法在现实生活中的应用。神经网络方法用于数据挖掘,是人工智能早期数据挖掘领域中使用的方法之一。它能更好地挖掘异常数据,但方法层数难以确定,时间复杂度相对较高。蚁群聚类算法是在聚类算法的基础上改进和推广的,能够达到异常数据检测的目的。然而,由于算法的随机运动,算法收敛速度慢,聚类时间延长。
结论
异常数据挖掘研究是一个有价值的研究课题,近年来吸引了越来越多学者的关注和研究。因此,异常数据挖掘算法取得了新的进展,并已广泛应用于生态系统分析、公共卫生、天气预报、金融领域、客户分类、网络入侵检测、药物研究等地方。希望本文的方法能为读者提供更多关于异常数据挖掘的思路,并能很好地将人工智能中的方法应用到异常数据挖掘中,克服各种方法的不足,使人们能够更好地应用它们。
参考
[1]克诺尔·阿洛思用于挖掘大数据集内基于距离的异常值[·C]//非常大的数据库(VLDB\'98)。纽约:国际会议进程,1998:392-403。
[2]布雷尼格·米,克里格勒·惠普·桑德,LOF:识别基于密度的局部离群值[·C]//ACM西格玛德会议录。[证交会]:[证交会,2000年。
[3]王新等。数据挖掘中聚类方法的比较研究。济南:山东师范大学管理学院,2006。
魏海坤,许思新,宋文中。神经网络的泛化理论和泛化方法[[]。自动化学报,2001,27(6):806-814。
庞胜利、吴美丽。人工神经网络在大型桥梁健康监测系统中的应用[。石家庄铁道学院学报,2002,15(2):63-65。
金伟。蚁群聚类算法分析[。计算机光盘软件与应用,2011,(13):199,202。
孙锦华吴克寿陈玉明。基于知识粒度的异常数据挖掘算法[。《计算机工程与应用》,2012,48(4):118-121。
苗多谦,王银,刘清,等。粒度计算:过去,现在和未来[。北京:科学出版社,2007。
苗多倩,樊氏董。知识粒度计算及其应用[。系统工程理论与实践,2002,22(1):48-56。


