基于预拷贝的迁移算法优化,当数据已满时,需要更长时间的预拷贝技术还是重建?...
基于预拷贝的迁移算法优化
当数据已满时,预拷贝技术和重建中哪一项需要更长时间...当数据满了时,哪种预拷贝技术和重建需要更长的时间和更多的计算资源?射手座爱白羊座99 2018-10-22 |浏览8个数据分析|报告
请简述预拷贝技术和重构技术的区别
随着虚拟机技术的快速发展,高性能计算环境对硬件平台的依赖得到了有效解决。虚拟机动态迁移技术支持无缝快速迁移,广泛用于改善系统负载平衡、容错入侵和节能管理。然而,内存状态迁移及其动态变化所涉及的大量数据逐渐成为研究热点。 复制到移动硬盘?它是片段文件还是视频文件,大约6-10个小时
当数据已满时,需要更长时间的预拷贝技术还是重建?...
当数据已满时,预拷贝技术和重建中哪一项需要更长时间...当数据满了时,哪种预拷贝技术和重建需要更长的时间和更多的计算资源?射手座爱白羊座99 2018-10-22 |浏览8个数据分析|报告
请简述预拷贝技术和重构技术的区别
基于预拷贝的迁移算法优化范文
本文的目录导航:
[标题]探索云存储容器的动态迁移技术??
[第1章]云环境中容器动态迁移技术研究简介
[第2章]云容器虚拟化和迁移技术
[第3章]基于最小迁移量的迁移算法优化
[第4章]基于预拷贝的迁移算法优化
[第5章]云容器动态迁移原型系统的设计与实现
[第6章]云数据动态迁移技术的结论与参考
第四章 基于预拷贝的迁移算法优化
目前,在基于容器的分布式云计算平台下,会出现集群负载不均衡的问题,因此需要将负载较高服务器中的容器迁移到其他相对空闲的服务器中。在第三章中的OMNM算法之后,热点容器和目标服务器都被挑选出来,进行容器具体的内存页迁移操作。传统的预拷贝方式忽视了内存页的特征,导致一些经常被修改的内存页在前期的预拷贝阶段被拷贝多次。因此,本章提出了一种优化的预拷贝算法(OPCA),引入预测模型,根据容器中有一部分的内存页经常被改变的特征,尽量把这些内存页放在最后的宕机拷贝里面进行,而在拷贝前期,去拷贝那些改变较少的内存页。
4.1 研究背景
在具体的容器内存迁移算法范畴,根据拷贝的顺序,主要分为预拷贝和延迟拷贝[42]
两个大方向。预拷贝就是先把内存页拷贝过去,再迭代拷贝脏页。延迟拷贝则是先宕机,把Docker容器的状态信息拷贝到目标服务器,等容器在目标服务器中重启之后,再开始通过网络连接传送内存页。两种拷贝方式都会有一段准备资源时间,预拷贝的性能表现依赖于当前容器中运行的应用和网络带宽,如果容器中的应用会产生大量脏页,则拷贝时间会延长,且性能会下降。而延迟拷贝的性能主要依赖于工作负载和网络链路速度。基于容器生命周期短的性质,本章选用预拷贝的方式来对迁移进行优化。而最典型的优化预拷贝算法有两类:一种是基于内存压缩的优化算法,另一种是基于预测的优化算法。
4.1.1 基于内存压缩的优化算法
此类算法的研究重心是在拷贝容器的内存时,采用内存压缩的方式,尽量的减少空白页的 拷 贝, 用 最少 的空 间 把内 存 信息 传输 过 去。 常 见的 内存 压 缩算 法 有LZW算 法(Lempel-Ziv-Welch),哈夫曼树,RLE(Run Length Encoding),Rice等。大部分压缩算法都是根据这些经典的压缩算法进行优化得到的。下面来介绍一下经典的LZW算法。
LZW算法[43]是一种比较经典的内存压缩算法,和哈夫曼树等算法都是属于无损压缩的范畴。它的核心思想是利用字符的可重用性,每当有一个新的编码输出的时候,就会有一个字符串存入字典中。算法之初,会把原始文件中的不同字符提取出来,然后根据这些字符的索引来替代原始文件中的相应字符,从而最终减少传输的文件大小。图4.1是LZW算法的流程:
由图4.1可知,LZW的算法是有局限的,它所适用的场景是原始数据中存在大量的重复串。重复的地方越多,LZW算法的表现就越好。反之,可能会毫无效果甚至是起到反效果。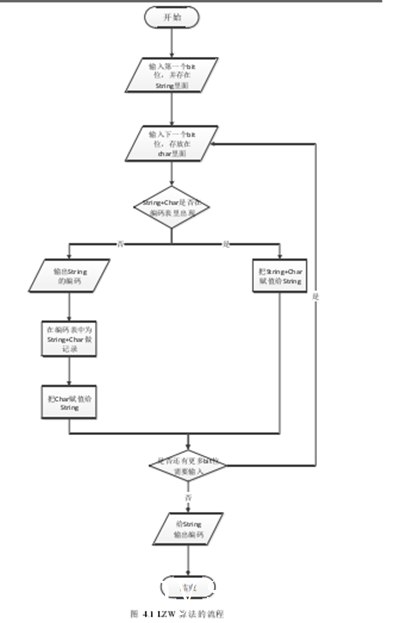
而在Docker容器云环境中,其内容的重复度如何,显然不容易去预知的。另外,此类压缩算法发展的比较成熟,优化的空间也比较小。所以现在的研究点集中在对内存页再更改率的预测上。
4.1.2 基于预测的优化算法
基于预测的优化算法是围绕内存页的预测展开的。一般的做法是根据内存页在一段时间内被修改的概率,计算该内存页再次被更改的概率。常见的预测模型有灰色模型,蚁群算法模型,回归模型AR(n)。例如常用的AR(n)模型[44],就是根据前几次的历史数据来预测下一个的数据。
假设在AR(n)模型中,已经观测到前k-1个值,分别为y1, y2, y3, … yk?1,那么根据模型可以计算出第k个值为:
同样,第k+2步的预测值可以由k+1步的观测值和前p-2步的观测值之和,其他值可以用同样的思路进行推导。
因为针对的是内存页的预测,所以对算法的精准度要求较高,像简单的预测模型是不够的,必须要增加修正模型。
4.2 传统的预拷贝算法
4.2.1 预拷贝模型
目前,大多数的容器迁移算法都采用预拷贝[45]的方式。其大概流程是先在第一轮迭代拷贝中将所有的内存页从源容器拷贝到目标容器中,然后将源容器中状态信息传送到目标容器中。预拷贝最大的优点就是可靠性。当拷贝失败的时候,可以恢复原先的状态。
如图4.2所示,在一开始的阶段,需要确定好待迁移的热点容器。之后发起迁移请求,开始进行容器内存页的拷贝过程。先进行第一轮拷贝,再迭代拷贝N次。为了让用户察觉不到停顿,迭代拷贝都是在容器运行的状态下完成的。每一次拷贝之后,容器中正在运行的应用在很大概率上会修改内存页,所以在下一次迭代拷贝过程中,还要对这些区域进行拷贝。
在第N轮迭代拷贝完成后,源容器会停止运行,将所有的脏页一次性拷贝到目的容器中,然后目的容器开启服务,继续完成用户提交的应用。
4.2.2 预拷贝算法的分析
预拷贝算法是一种比较常见的内存迭代拷贝方式,但其最大的缺点就是没有对内存页的特性进行细致的分析。有的内存页是属于高脏页率[46]的内存页,每一次迭代拷贝的时候,都会发现此内存页重新成为脏页,这就意味着每一次迭代拷贝过程都需要把该内存页拷贝过去,无形中增加了拷贝的数据量。最好的解决办法就是能够对这些内存页做预测分析,对于那些高脏页率的内存页,可以放到后面,甚至是最后一轮拷贝中进行。
4.3 优化的预拷贝算法
4.3.1 OPCA 的迁移模型
在传统迁移模式的基础上,增加了一个预测模块用于对内存页修改状况的统计,用来收集相关数据,作为算法的原始数据。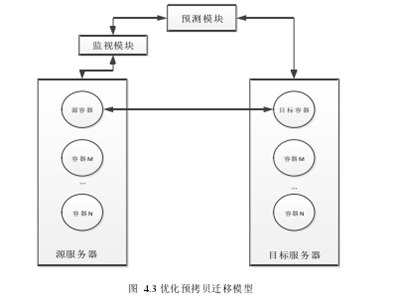
如图4.3所示,从源服务器上迁移源容器到目的服务器中的目的容器。监视模块一直在收集容器中每个内存页的读写状态,如果内存页被写入就标记为1,只读或者其他不影响内容的操作标记[47]为0.监视模块得到的数据被传送到预测模块,在每次迭代拷贝内存页的时候,对脏页再次被修改的概率进行一个预测,如果概率较高,则放在最后一次迭代中进行,如果概率较小,则直接进行拷贝。本章提出了OPCA,通过结合灰色模型和马尔科夫预测模型,对脏页再次被修改的概率进行预测,选取长期保持高修改概率的脏页进入热工作集,留到最后一次进行拷贝,而对概率较低的进入冷工作区,直接进行拷贝。
4.3.2 工作区的划分
为了更好的提高拷贝的效率,避免冗余传输,这里引入了工作区的概念。现在把工作区域分为下面几种:(1)空闲工作区(Free Workspace):只被读取或者不做任何操作的工作区域,不参与脏页拷贝过程。(2)总工作区(Total Workspace):
即参与脏页迭代拷贝过程的区域,按照脏页再次被修改的概率具体分为三个区域,冷工作区(Cold Workspace),温工作区(Warm Workspace),热工作区(Hot Workspace)。冷工作区是脏页再次被修改概率较低的一个区域,参与每次的迭代拷贝。这里引入温工作区的目的是在前期内存状态数据较少时,减少不必要的误差,同时也起到一个分层拷贝的作用。热工作区存放的是被修改概率高的内存页,放到最后一次拷贝过程中进行。(3)脏页集(Dirty Set):当前被修改的内存页集合。(4)发送集(Send Set):最终发送的脏页集合,不包括在预测过程中变成脏页的那部分内存。其中,总工作区是迭代拷贝涉及到的主要区域。图4.4展示了总工作区域中各层次工作区与脏页集之间的关系。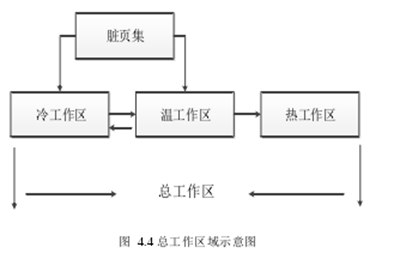
如图4.4所示,总工作区被分为三个层级。冷工作区和温工作区与脏页集的关系十分密切,根据一定的条件,脏页集中的内存页会被标记在冷工作区或是温工作区。另外,冷工作区与温工作区中的内存页会互相交换,而温工作区中的内存页升级到热工作区中后不会降级。
4.3.3 预测模型的选择
在云计算的环境下,常用的容器,例如Docker容器,它的运行较为灵活,内存的大小差别较大,运行的应用类型也各不相同,所以得到的内存状态数据比较不均匀。相比较传统的灰色模型,灰色马尔科夫模型GMM更准确,更适合这种不均匀的情况。
现在先建立GM(1,1)的灰色模型,求出预测曲线。设原始的脏页被修改率数据为:
其中,p(0)是数据的集合,里面有N个数据。现在对数据集中的数据做累加处理,得到新的集合:
4.3.4 OPCA 的算法流程
为了解决在传统预拷贝机制下的传输过程中,误把低修改率的内存页传输到热工作集的问题,提出了温工作区的概念。在4.1节已经对工作区的划分做了详细的解释,温工作区就是为了避免误差操作的同时,起到一个分层的作用。下面分三个阶段来阐述优化拷贝机制:
阶段1:在前期数据较少的时候,在第n次迭代拷贝中,通过灰色马尔科夫预测模型,得到当前脏页集中的每个内存页再次被修改的概率pi.若pi ε1,则放入温工作集。因为前期的时候数据量较少,如果直接把高修改率的内存页放入热工作集,会造成后期停机拷贝时间延长。现在,把高修改率的内存页暂时放入温工作集。在这个阶段,每次只拷贝冷工作集中的脏页。在预测阶段被修改的页不在考虑范围之内,留到下一轮拷贝中进行。
阶段2:而在后期数据较多时,在第n次迭代拷贝中,仍然通过预测模型得到pi,并通过阈值ε1决定当前脏页放到冷工作集CW或者温工作集WW.同时,温工作集中的内存页会更新概率数据。对于脏页集中每个内存页Mi∈ DS,若(Mi? WW)&(pi> ε1),则把Mi放到WW中,而如果Mi∈ WW,即已经属于温工作集了,则要根据pi的最新值进行重新分区。若pi ε2则直接放入到HW.
阶段3:当温工作区的大小比较稳定时,热工作区被最终确定,按照传统的迁移模型继续迭代拷贝直到结束。
图4.5是OPCA的算法流程: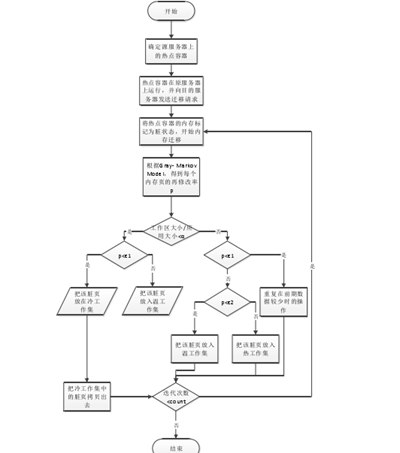
图4.5展示了OPCA的算法流程,可以看出,OPCA先通过优化后的GMM,得到内存页再次被修改的概率,然后根据工作区的划分,去分别存放不同类型的内存页。同时每次迭代拷贝过程中,都会去动态的更新工作区的内容,保证下一次拷贝的准确性。
通过优化的预拷贝算法之后,可以在保证相同的迁移时间的情况下,有效的减少宕机时间,提高用户的体验。
4.4 仿真分析
4.4.1 仿真参数设置
为了更好的模拟出真实的云测试环境,生成100台虚拟服务器作为模拟实验的环境。实验中,首先针对点对点容器的迁移进行了实验,验证算法的精确度。最后,模拟集群容器的迁移,通过生成若干容器,得到集群环境中OPCA迁移的稳定性。另外,为了保证实验的有效性,分别为LZW算法和AR(n)回归算法建立模型,一起进行比较。表4.1展示了实验中虚拟服务器的一些参数值:
4.4.2 性能指标
为了衡量的算法OPCA是否有效,这里主要从三个方面来进行衡量:
(1)宕机时间:宕机时间就是在最后一轮停止Docker容器服务,把剩余脏页全部拷贝所用的总时间。宕机时间牵扯到用户体验,所以是优化算法的一个重要指标。
(2)迭代拷贝次数:迭代次数直接影响到了拷贝的效率,如果次数比较多,说明拷贝了很多高更改率的内存页。
(3)总拷贝时间:将源容器完整的迁移到目的容器,所花费的总时间。
为了更好的模拟现实中的环境,用Device Mapper调整容器的大小,并分别运行了低脏页率和高脏页率的应用。在这两种情况下,分别得到了宕机时间和总拷贝时间。
4.4.3 仿真结果分析
在实验的第一部分,为了测试算法的精确度,模拟单个容器从源服务器到目标服务器这种点到点的迁移方式。所以分别设置待迁移容器的内存大小为64,128,256,512,1024(MB),这样范围会尽可能的广,减少不必要的误差,同时也可以观察出数据的增长趋势。
图4.6表示的是在低脏页率的情况下,PCA,OPCA,LZW和AR模型的平均迭代次数的比较。可以发现,随着容器内存的增大,迭代次数呈增加的趋势。而且,在低脏页率的情况下,OPCA的迭代次数平均比PCA低1次。另外,可以发现LZW模型的波动幅度较大,一开始呈现增长趋势,在容器内存大于256MB时,又呈现下降的趋势。因为容器的内容是随机的,其内部是否存在大量重复的部分没有很好的办法进行预测,所以在这种情况下,LZW相比PCA是有一定的优化效果,但是波动性较大,相对来说不是很稳定。
AR模型在低脏页率的情况下,和OPCA的平均迭代次数相差0.4次,OPCA的迭代次数相对较少。从图4.6可以看出,当容器占用内存较小时,OPCA的迭代次数比AR的迭代次数略少一点,当容器占用内存较大时,两种算法的迭代次数保持在相当的水平。综合来讲,OPCA的算法优化效果很明显,同时比LZW和AR模型的平均迭代次数低。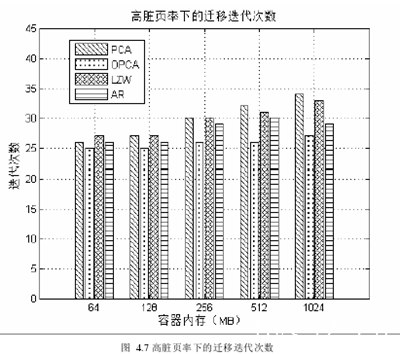
图4.7则表示的是在高脏页率的情况下,PCA,OPCA,LZW和AR模型的平均迭代次数的比较。与图4.6相比较可以发现,在高脏页率的情况下,OPCA的迭代次数要明显小于PCA,平均次数少3.8次。而且,当容器占用内存大于256MB时,优势更为明显。
LZW算法波动性大,在容器占用内存小于256MB时,比PCA的平均迭代次数高0.5次。在容器占用内存大于256MB时,LZW的平均迭代次数比PCA低1次。所以LZW这种内存压缩的方式对容器的内容要求很高,如果重复度不高,优化的效果很弱。
AR模型的整体优化效果较好,但是平均迭代次数比OPCA高了2.1次。在容器内存占用量在256MB和512MB的规模时,OPCA的迭代次数明显比AR模型少,此时OPCA的修正策略起到了效果。
综合来说,在高脏页率的情况下,OPCA的优化效果很明显,无论是精确度和稳定的程度。所以,从迭代次数的角度来看,OPCA很有效的优化算法。下面来从宕机时间来测试OPCA的有效性。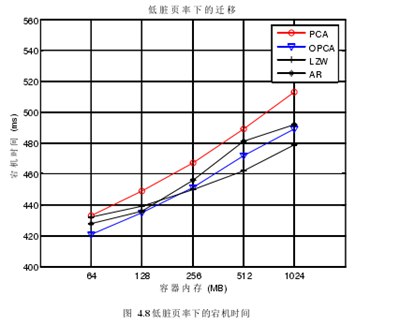
宕机时间是在停机拷贝的阶段,容器状态数据和剩余脏页全部拷贝到目标服务器的时间。
此时容器的服务是需要停止运行的,所以称之为宕机时间。在低脏页率的情况下,将PCA与OPCA的宕机时间的比较后,得到了图4.8.其中,可以看到,随着内存的增大,总体的宕机时间呈增长的趋势。在低脏页率的情况下,OPCA和PCA宕机时间相差的还是比较大的,当容器内存占用达到了1024M,两种算法下的宕机时间相差到30毫秒,这在点到点的迁移过程中,是比较大的差距。
LZW由于其压缩算法的优势,在停机拷贝时,所花费的时间会比其他算法要少,所以在容器内存占用较大时,LZW算法是比OPCA表现的要好的,最快的时候可以比OPCA快10毫秒。
AR模型作为与OPCA同类型的算法,总体表现不如OPCA,平均宕机时间要比OPCA慢了几毫秒。
宕机时间在某种程度上代表了停机拷贝前,容器内剩余的脏页的总大小。因为容器的状态数据一般都不会占用太多空间。所以OPCA虽然没有LZW的平均宕机时间短,但是相比PCA,AR模型,宕机时间相对较短。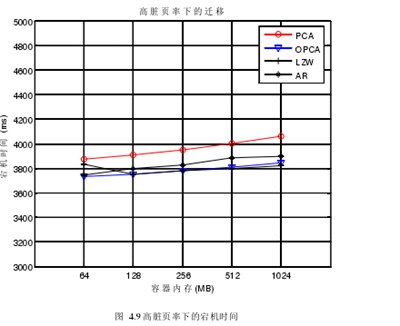
图4.9阐述了在高脏页率的情况下,PCA,OPCA,LZW和AR模型的宕机时间。可以看到,在高脏页率的情况下,宕机时间的增长趋势比低脏页率的情况较缓。另外,在高脏页率的情况下,OPCA的预测效果很明显,宕机时间要明显比PCA的短,最好的时候可以快2000毫秒,这是很明显的优势。但是LZW整体的表现比OPCA要好,这是由于LZW和OPCA的算法机制不同造成的。
LZW每次拷贝都会用压缩算法,OPCA则是用标记的方式,只拷贝被修改的内存页。但是相对于同类型的AR预测模型,OPCA的优势还是比较明显的,不论容器的占有量是大还是小,OPCA的宕机时间都要比AR模型要少。
所以,在高脏页率的前提下,对于宕机时间这个指标,OPCA的优化表现是很明显的,比PCA和AR模型表现的都要好,但是相比LZW要差一点。
图4.10阐述了传统的优化后的算法下,PCA,OPCA,LZW和AR模型的迁移总时间。
总的来说,OPCA的优化效果很明显。因为优化算法必然会在算法的执行过程中消耗一部分时间,所以如果总时间仍然可以比PCA少,则足以说明优化算法的有效性。
OPCA算法下的平均迁移总时间比PCA要快4秒左右,当容器内存较大时,可以快5秒左右,这在点对点的迁移过程来说,是比较不错的进步。
LZW的优化效果不明显,因为每次都用压缩的操作,势必会给减少总迁移时间带来压力。而如果将LZW与预测结合,则会执行两套算法模式,不仅算法复杂度会增加,还需要额外的存储空间,有效性很难保证。对于同类型的AR预测模型,显然OPCA的精确度更高,总迁移时间更少。
所以,虽然OPCA的宕机时间没有LZW的短,但是总的迁移时间比LZW的要少。接下来测试在模拟整个集群去进行容器迁移时各个算法的效率。
初始时,分别在64,128,256,512,1024(MB)5个级别散列容器在服务器集群中,设定整个服务器集群的负载均衡率μ=2,且存在服务器的内存占有率在80%的现象。每次以迁移最大容器为原则,一直迁移到阈值μ = 0.5为止。测试的结果如图4.11所示:
可以从图4.11中看出,在集群的环境中,OPCA是最快把负载均衡率从2降到0.5的算法,仅仅花费了120秒。紧接着的算法是AR预测模型算法,在140秒左右把负载均衡率降到0.5.
LZW的整体表现不是很好,负载均衡率没有很快的降下去,在150秒的时候还没有把负载均衡率降到阈值0.5,甚至没有优化前的PCA表现的好。从负载均衡率的角度可以看出,OPCA的效果是很明显的,可以在较短的时间内让服务器集群重新保持负载均衡。
4.5 本章小结
从减少宕机时间的角度入手,优化了传统的预拷贝算法,提出了灰色马尔科夫预测模型和新的工作区的概念。通过更改概率的预测,来实现工作区的划分。将高更改率的内存页放入热工作区,留到最后拷贝过程中进行。另外,引入了温工作区之后,降低了热工作区的判断误差,避免不符合条件的内存页被误放入到热工作区。仿真实验证明,OPCA在保证总迁移时间不高于PCA的前提下,较好的减少了迭代次数和宕机时间,总体表现比LZW和AU预测模型都要优秀。最终提高了资源的利用率,且增强了用户的体验。


