云存储及其相关技术,与云计算和云存储相关的信息技术有哪些?
云存储及其相关技术
与云计算和云存储相关的信息技术有哪些?云计算是分布式计算、并行计算、实用计算、网络存储技术、虚拟化、负载平衡,
云存储的底层关键技术有哪些
云计算的关键技术是分布式处理、并行计算和网格计算等概念的开发和商业实现。其技术本质是对计算、存储、服务器、应用软件等信息技术软硬件资源的虚拟化。云计算在虚拟化、数据存储、数据管理、编程模式等方面有其独特的技术。 联想云存储系统是云计算的关键技术。联想云存储系统是一套面向教育、政府和企业等客户的应用系统和存储解决方案。联想云存储系统集成了大量不同类型的存储设备,通过集群应用和分布式存储技术协同工作,提供企业级数据存储、管理、业务访问和高效协作。 联想云存储系统优势:完善的系统级功能;对于初创公司来说,成本有点高。 当云计算系统中计算和处理的核心是大量数据的存储和管理时,云计算系统需要进行配置 云存储技术可以实现什么功能?1、云企业网络磁盘传输技术加密传输断点连续传输二次传输再压缩传输2、云企业网络磁盘存储技术采用非结构化1、维护简单的云存储提供集群管理模式,用户只需要登录到云存储系统的一个IP地址,就可以看到所有存储设备的状态、相应的磁盘状态以及整个存储空间的使用情况 该系统还将针对不同的异常和故障问题及时发出警告通知和日志记录,大大简化了管理。云技术是指云计算的一些技术,包括虚拟化、分布式计算、并行计算等。除了技术,云计算还指一种新的信息技术服务模式。可以说,目前提到的云计算有30%是技术,70%是模型。 云存储平台通常可以被理解为具有N个多服务器和存储的云计算服务提供商。
与云计算和云存储相关的信息技术有哪些?
与云计算和云存储相关的信息技术有哪些?云计算是分布式计算、并行计算、实用计算、网络存储技术、虚拟化、负载平衡,
云存储的底层关键技术有哪些
云存储及其相关技术范文
本文的目录导航:
[标题]探索云存储系统的云数据放置优化方法??
[第1章]云存储系统云数据放置方法研究导论
[第二章]云存储及其相关技术
[第3章]云数据多目标存储模型
[第四章]基于多目标遗传算法的云数据放置策略
[第五章]云数据放置实验与分析
[第六章]云数据布局优化方法的结论与参考
第二章云存储及相关技术
本章主要介绍云存储以及与本主题相关的相关技术。包括云计算的相关概念和分类及其最基本的核心理念虚拟化技术。其次,重点介绍云存储技术,包括相关概念、应用分类和系统架构。最后,对Hadoop中的HDFS文件系统进行了深入研究,并对HDFS的实现模式进行了分析,为接下来的章节提供了理论依据。
2.1云计算概述
2.1.1云计算概念
随着互联网时代的飞速发展,计算机硬件升级的速度非常快。
英特尔创始人之一戈登·摩尔曾在1965年提出,当价格保持不变时,集成电路中可容纳的元件数量将每两年翻一番,其性能将是[的两倍。这一规律揭示了互联网技术的快速发展,硬件的快速发展导致了大量的闲置资源。这些资源除了自身老化之外,还有性能缺陷。云计算的出现不仅解决了大量闲置资源的问题,也节约了互联网资源。此外,通过其集群技术、网格计算、虚拟化、分布式文件系统等技术,实现了设备间的协同工作,使得多个硬件设备可以统一向外界提供相同的服务(3)软件作为服务软件,针对性最强。运营商将用户所需的功能打包到软件服务中。与基础设施即服务和平台即服务相比,软件即服务既不提供硬件资源,也不提供特定的系统环境。用户只能使用特定的软件通过网络完成特定的功能操作。,并提供高质量的计算、存储等功能。
此外,用户不需要知道“云”中的设备信息和部署细节,也不需要掌握相关专业知识,也不需要直接控制。
然而,目前全球还没有统一的云计算定义和标准。
NIST(国家技术和标准局国家雷达技术研究所)将云计算定义为访问者可以通过互联网配置和共享所有云资源的模式2.1.3虚拟化技术。共享云资源包括网络、存储和应用程序等。资源库通常以最低价格控制资源,并依赖服务提供商的应用程序接口来实时获取和释放云资源云计算是并行计算、分布式计算和网格计算发展的延伸。它整合了虚拟化[36、公共计算、Iaa、PAA和Saa的概念,形成了一个新的框架。云计算的概念不同于网格计算。前者旨在集中管理和分散使用资源,而网格计算的思想是整合和分散集中使用资源。云计算在服务器端集中提供计算资源。为了节约成本和最大化空之间的利用率,有必要通过虚拟化技术建立资源库,这是云计算的基础和重要组成部分。。根据维基百科对云计算的定义,它是一种基于互联网的计算方法,可以实现软硬件资源和数据的共享,并根据用户的需求为用户提供各种终端和其他硬件计算机科学家大卫·惠勒(David Wheeler)曾有一句名言,“计算机科学中的任何问题都可以通过添加一层逻辑层[37来解决”,虚拟化的思想是在系统中构建一层,这实质上是将特定资源抽象成逻辑资源,也就是说,各种基本资源在虚拟化处理后被表达为虚拟化资源。此外,单个物理资源可以被映射到多个虚拟化资源(3)存储虚拟化存储虚拟化是一种有效的数据存储模式,也是云存储的重要基础。存储虚拟化是通过虚拟化技术将相同或不同、相邻或远程物理存储设备抽象到存储设备中。它的内部结构对用户是透明的。实现存储虚拟化有两种方式,即硬件存储虚拟化和网络存储虚拟化。。它为云计算提供了自适应和自我管理的灵活基础架构。通过虚拟化技术,可以扩展硬件的逻辑容量,简化软件的配置过程。基于此,云计算为不同用户分配逻辑资源,提供相互隔离、安全可靠的工作环境,实现各种工作模式的快速部署。。
Galibus T将云计算定义为能够提供大规模分布式计算的高效信通技术(信息通信技术)架构。它包括虚拟化资源、并行处理、数据安全和大规模数据存储。云计算不仅可以最大限度地降低个人和企业自动计算的成本和限制,还可以提供低成本的硬件设施、高效的管理和用户访问模式[33】。

2.1.2云计算分类
根据部署模式和服务目标在云计算平台中,信息技术资源、硬件、软件、操作系统、网络存储等。都可以成为虚拟化对象。我们可以根据不同的虚拟化对象将虚拟化技术分为网络虚拟化、系统虚拟化和存储虚拟化2.2云存储技术:的不同,云计算可以分为公共云、私有云和混合云:
(1)公共云公共云体现了云服务的公共性质,不属于个人用户。公共云(Public Cloud)是向所有用户提供资源的公共服务,通常通过国际数据中心运营商或第三方提供相关云服务。对于中小企业来说,采用公共云可以有效降低成本,并在以后的扩展中具有优势。它的缺点也是显而易见的,包括对云数据的控制不足以及难以确保云数据的安全性。
(2)私有云私有云是公共云的扩展和优化。与公共云相比,最大的区别在于它是为一个用户单独分配的。用户之间没有存储空的交叉,从而大大提高了数据安全性和云服务的质量。相比之下,私有云因其特性而构建和维护成本高昂,因此通常通过收费向用户提供。
(3)混合云混合云(Hybrid cloud hybrid cloud)结合了公有云和私有云的优缺点,通过有效的策略将两种云有机地结合起来,为用户提供服务,从而达到最佳的云计算效果。例如,在混合云中,可以为具有高用户隐私或高质量服务需求的数据操作提供私有云服务,而公共云服务可以用于降低其他相对次要需求的成本。目前,混合云的研究还处于起步阶段,但具有很大的研究价值和应用前景。
根据其服务类型,云计算可分为基础设施即服务(IAAS)、平台即服务(PAA)和软件即服务(SAAS),(1)网络虚拟化网络虚拟化是各种网络软硬件资源的有效整合,为用户提供虚拟网络连接服务。网络虚拟化通常包括虚拟局域网(VLAN)和虚拟专用网(虚拟专用网)。虚拟局域网(VLAN)是一些物理局域网的集成,使它们在集成后成为一个单一的局域网。这个过程对用户是透明的。目前,大型制造商的数据中心规模不断扩大,导致内部人员过剩和效率低下。数据中心可以采用虚拟局域网的方式进行优化,以改善内部结构,提高运行效率。虚拟专用网虚拟化广域网并抽象网络连接,以便远程用户可以通过虚拟连接(如物理连接)随时访问组织内部的网络。使用虚拟专用网可以提高外部网络连接的可靠性。。
(1)基础架构即服务基础架构即服务通过虚拟化将硬件设备等基本资源封装到云设备中,并通过网络将其提供给用户。用户可以远程控制像计算机一样使用这些云的远程设备,只需要支付低成本的使用费。用户可以在这些虚拟化硬件上安装视窗或Linux及其他系统来运行应用服务。
(2)作为服务平台和服务,平台是服务提供商为用户提供运行应用的操作环境。它相当于一个操作系统。该服务为用户提供所需的操作环境和云计算能力。用户可以在此环境中开发、部署、运行、测试和其他操作。用户不需要考虑操作环境的配置和维护,但是他们的自主性是有限的。通常由于操作环境的限制,他们只能根据有限的模型来解决问题。因此,平台通常被用作解决特定问题的服务。
[29]
[30]
[31]
[32]
虚拟化是接口抽象、封装和标准化的分层过程。在封装过程中,虚拟化技术将屏蔽硬件的物理差异,如模型差异、容量差异、接口差异等。磁盘阵列技术是根据存储虚拟化的实现原理,将多个磁盘组合成一个磁盘阵列。由于虚拟化的特点,磁盘碎片整理技术可以将廉价且低性能的磁盘硬件回收到具有更高性能的统一存储设备中。网络存储虚拟化将存储设备和管理系统结合在网络连接中。在这种模式下,存储设备的地理位置可以不同,并且对用户是透明的,用户可以使用管理员权限来管理存储在这些设备上的数据。基于网络的存储虚拟化的实现主要包括网络连接存储(网络连接存储)和存储区域网络(存储区域网络)。。这样,在虚拟化处理之后,硬件资源将以标准化和一致的操作界面呈现给上层。这样,在硬件上部署虚拟化产品后,上层企业就可以摆脱与硬件细节相结合的设计。然而,虚拟化并不是万能的,它不负责解决计算问题,它通常只与硬件相结合来构建物理资源的资源库。
[34]
[35]
目前,服务提供商为网络虚拟化技术添加了新概念。对于网络设备供应商来说,网络虚拟化是加强和扩展以前的网络设备,包括路由器、交换机、网桥等。使这些设备更具可扩展性,并提供更多应用,如防火墙、互联网协议语音(Vo IP)、移动通信服务等。虽然网络虚拟化已经取得了一些成果,但还远远不够,还有许多问题需要解决,包括适应更大的网络环境和检测虚拟化网络。
(2)系统虚拟化系统虚拟化通常也称为服务器虚拟化,是用户最常接触的虚拟化类型。例如,使用虚拟化软件(如VMware server)在计算机上构建虚拟机,用户可以在虚拟机上安装ubuntu和其他系统以及相关系统兼容的应用程序。实际操作虚拟机相当于使用真实的计算机。系统虚拟化的核心内容是通过虚拟化软件在硬件设备上创建一个或多个虚拟机。这些虚拟机在同一个设备上运行,但实际上它们不会相互干扰。每个虚拟机作为一个实体具有相同的硬件功能和操作系统,同一硬件设备的多个虚拟机可以安装不同的操作系统,从而在一定程度上扩展了硬件设备的功能。
[38]
[39]
[40]
2.2.1云存储概念
云存储是在云计算的基础上衍生、扩展和发展的。它是一个以数据存储和管理为核心的云计算系统。云存储将由大量异构存储设备组成,通过网络形成存储资源池。它集成了多种云存储技术,如分布式存储、多租户共享、数据安全、重复数据消除等。它通过统一的网络服务接口为授权用户提供灵活、透明和按需的存储资源分配云系统。这是大数据时代传统存储技术自然发展的结果。
云存储的主要思想是高冗余和虚拟化的聚合[41]。高冗余设计是为了确保生命周期中数据的可靠性和可用性,是云存储系统的设计重点之一。回顾过去,为了确保互联网在遭受核攻击后能够继续工作,设计师们采用了高度容错的设计。例如,端点之间的路径是冗余的,信息在分组后通过不同的路径传输,丢失的数据包根据重传机制确保数据完整性。这些高度冗余的设计使云存储系统能够在整体水平上实现高容错。例如,在云存储系统中,数据的多个副本存储在不同位置的多个服务器上。这样,当一些服务器出现故障时,系统只需要更改指向存储对象位置的指针。
亚马逊AWS[42]在其Iaa系统中采用了高度冗余的设计,允许在四个数据中心中的任何一个创建EC2虚拟机实例和S3存储容器。用户可以在亚马逊系统中合理分配数据,并通过高冗余设计确保系统的高可用性。虚拟化技术可以实现云存储资源的高效聚合,消除资源差异,通过一致的抽象接口实现资源的同质化。通过虚拟化技术,可以实现硬件聚合和数据聚合,以帮助企业降低运营成本和保护现有投资。
Net App的存储虚拟化软件存储网格(Storage GRID)可以创建一个虚拟化层,通过管理系统将不同的存储设备聚合到一个存储池中。通过它,可以构建PB级存储池,该存储池可以兼容不同的存储设备、不同的传输协议和不同的地理位置。
与传统存储系统相比,云存储具有硬件成本低、管理成本低、能耗成本低、资源利用率高和服务能力强的优点。云存储系统由大量廉价的存储设备组成,通过多拷贝技术实现了强大的容错能力,使企业能够用低端硬件取代高端硬件,一些面临淘汰的过时硬件也可以继续在云存储系统中使用。云存储系统通过虚拟化技术汇集资源,实现高度自动化的管理,无需人工干预,大大降低了管理成本。传统的存储系统资源利用率很低。它以静态方式分配存储资源,并且浪费了大量的保留空。在云存储系统中,通过服务器整合和重复数据删除技术,可以大大降低不必要的存储开销,从而提高存储资源的利用率。当用户使用云存储服务时,他们不需要关心存储基础架构的实施细节或底层业务灵活性和风险抵御能力。相反,他们可以获得适当的资源,并根据实际需要支付费用。用户可以通过各种网络设备访问和管理数据。
2.2.2云存储分类
云存储根据管理类型可以分为不可管理云存储和可管理云存储。非可管理性云存储应用程序提供软件即服务(Saa S)类型的网络服务,而可管理性云存储应用程序提供基础设施即服务(Iaa S)类型的网络服务。具体类别如下:
(1)不可管理的云存储在不可管理的云存储中,存储服务提供商为用户提供存储容量,但限制存储容量、使用和客户端应用。对于用户来说,管理这种存储的选项是有限的。然而,另一方面,不可管理的云存储具有可靠性高、成本低和操作简单的优点。大多数面向客户的云存储应用程序都无法管理。
不可管理的云存储服务为用户提供磁盘空之间的分区作为特定容量。换句话说,远程存储作为映射驱动器出现在文件夹中。文件托管服务允许用户读写驱动器,在某些情况下,用户可以与其他用户共享驱动器。随着不可管理的云存储产品的逐渐发展和成熟,云存储供应商已经开始提供增值软件服务,如文件夹同步和备份。国外非托管存储的典型产品包括微软Onedrive和谷歌drive,国内非托管云存储产品包括百度云盘、华为网络盘和清华大学设计的海盗船系统。
(2)可管理云存储可管理云存储的主要用户是开发人员,他们使用可管理云存储为提供网络服务的应用程序存储数据。可管理云存储将存储空呈现为本机磁盘,并将提供给用户进行配置和管理。它由用户进行分区和格式化。可管理的云存储资源可以同时提供给应用程序和其他用户。
许多外国信息技术巨头提供托管云存储服务,如亚马逊AWS和微软Azure。易管理云存储在中国发展迅速,中国人民解放军理工大学开发了ariyun OSS、百度BCS、qiniuyun和Mass Cloud等行业。
2.2.3云存储的系统结构
2009年4月,存储网络行业协会(SNIA)主持组建了云存储技术工作组TWG。该组织的主要任务是引领云存储的发展方向,并引领全球存储行业的发展、推广标准、技术和培训服务。目前,该组织发布了关于云存储规范的云数据管理接口(CDMI) [43]的第一版,该版本为数据对象、存储容器、计算、计费、性能、队列、元数据等建立了相对完善的规范。与传统存储系统相比,云存储系统是由网络设备、存储设备、服务器、应用软件、公共访问接口、访问网络、客户端程序等组件组成的复杂系统,提供安全、可靠、高效的数据存储和服务访问服务。云存储系统的体系结构可以从上到下分为四个级别,如图2.1所示。
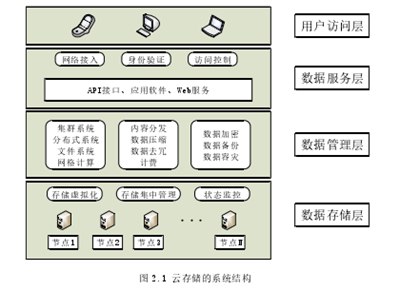
(1)用户访问层(User Access Layer)用户访问层是云存储系统应用的入口,是云存储架构的顶层。授权用户可以使用客户端或网络登录和访问云存储系统,以执行相关的存储操作。不同的云存储产品将采用不同的访问类型和方法。
(2)数据服务层数据服务层是云存储系统中与用户访问层接口的部分。它为用户接入层提供交互协议和编程接口,实现网络接入、身份认证、接入控制等功能。应用接口层是四层体系结构中最灵活的一层,主要体现在应用服务接口、应用软件和网络服务的多样化上。
(3)数据管理(Data Management)数据管理层是云存储系统架构中最重要的部分,它使大量存储设备能够协同工作,并通过虚拟化相关技术提供稳定、高质量的服务。数据管理层向上接收用户的相关数据并提供数据检索方法,向下管理数据存储层以确定数据存储方法。
(4)数据存储层(Data Storage Layer)作为云存储系统的最低和最基本的部分,数据存储层的主要功能是在云环境中存储数据。这一层的结构是由大量低成本的存储硬件设备通过网络连接组成,形成大容量、高可靠性、高安全性的存储集。这一层还包括存储虚拟化、实时状态监控和集中管理。数据存储层中的设备可能包含多种类型,分布在不同的位置,甚至世界各地。云存储系统通过网络将这些存储设备连接在一起,以实现集中管理和统一分发来存储数据。
2.3分布式文件系统
2.3.1分布式文件系统概述
分布式文件系统[45]是云存储系统的重要技术之一。随着互联网数据规模越来越大,并发请求越来越高,传统的关系数据库系统已经不能满足性能、价格和可扩展性的要求。
谷歌和亚马逊等互联网公司已经将超大规模分布式存储系统引入后台基础设施,以解决海量数据的存储问题。
作为操作系统的主要组成部分,文件系统的功能是为系统中的所有文件提供统一的管理和存储服务,并为用户提供通用和标准的接口。用户可以使用这些系统接口来访问、删除和复制存储在系统中的文件。传统的文件系统由于基于本地磁盘的特点,存在一些缺陷。一方面,因为所有文件都存储在一个磁盘上,即使磁盘是内部备份的,只要磁盘损坏,所有文件都会丢失;另一方面,这种存储方法难以扩展,其内存空有限,因此无法满足大量数据存储的要求。然而,分布式存储系统可以在不同的物理设备上存储数据,并且这种数据的分散存储模式可以与地图缩减并行计算框架[46]很好地结合,为大数据处理提供有效的实现方法。与传统的单一存储模式相比,分布式存储具有低成本和高扩展性,可以弱化关系数据库模型,获得高并发性和高性能。
分布式文件系统在云计算相关产业的发展中发挥着不可替代的作用,但也面临着数据存储的可靠性和一致性问题。为了解决这些问题,谷歌提出了GFS(谷歌文件系统)分布式文件系统。受GFS的启发,更高性能的分布式文件系统相继出现,如HDFS、TFS、Lustre FS等。虽然这些分布式文件系统的实现方法相似,但它们也有自己的优势。下面将重点介绍HDFS,为后面的章节提供理论基础。
2.3.2 Hadoop分布式文件系统
HDFS·[47](Hadoop分布式文件系统)是基于分布式系统架构Hadoop的分布式文件系统,是谷歌GFS分布式文件系统的优化结果。其设计的目的是使用过时或低性能的机器来构建稳定、高性能的分布式存储系统。
HDFS采用主从架构模式。在系统的节点群集中有一个名称节点和多个数据节点[48]。
名称节点(Name Node)是一个控制节点,其功能是将文件块的特定位置存储在物理存储器中,并控制对整个系统中文件的一系列访问。
数据节点通过执行名称节点命令执行特定操作,如打开、关闭和重命名系统中存储的文件。
数据节点是从节点。它的主要功能是管理存储在其所在节点上的所有数据。在实际存储数据节点之前,每个文件将被分割以生成一个或多个文件块,并且分割的文件块将被存储在每个数据节点中。
数据节点主要负责用户读写文件的请求。
作为辅助控制节点,辅助名称节点负责备份元数据信息,元数据是数据的描述,名称节点中的元数据信息保存在FSImage和编辑日志中,辅助名称节点的作用是定期将这两个文件从名称节点复制到本地目录,该操作是为了确保当名称节点停机时,HDFS可以通过备份文件恢复到停机前的状态。
数据节点和名称节点之间的连接是通过心跳机制实现的。数据节点需要定期向名称节点发送心跳。一旦名称节点在规定周期内没有从名称节点接收心跳,则认为数据节点的连接断开。它不能再运行了,最后将这个节点标记为“死节点”。类似地,当名称节点接收到新添加或断开的数据节点发送的心跳时,它可以根据心跳中包含的相关信息将该节点添加到节点群集中。这种模式使HDFS具有良好的可扩展性。
HDFS分布式文件系统主要用于处理大型文件。因为它可以接受一个文件的多个访问请求,所以它适用于高并发性的环境。它适合为大数据分析、网络爬虫和搜索引擎等具有高并发性要求的应用提供存储服务。相反,HDFS通常不用于存储大量小文件,因为名称节点(Name Node)在运行时需要将所有文件的元数据加载到内存中,每个元数据包含大约150KB的信息。由于这些内存的额外开销,名称节点的内存大小直接限制了HDFS可以包含的文件数量。
接下来,我们将研究HDFS的数据读写操作:
(1)HDFS数据写入过程(a)当需要写入数据时,系统将首先向名称节点发送文件创建请求。
名称节点首先确定系统中是否存在具有相同文件名的文件,如果存在,则拒绝该请求。
其次,系统首先将新文件的相关信息添加到文件系统的目录信息中,然后授权系统创建新文件。
在收到授权信息后,系统写入文件,首先剪切文件,然后分块写入。存储每个文件块时,系统首先为数据节点应用名称节点,然后写入文件块。
因为HDFS必须为每个数据块保存三个副本,所以在写操作中,对于每个数据块应用程序,名称节点返回三个数据节点的位置以存储数据块。数据块写入第一个数据节点后,数据节点会将数据块发送到另外两个数据节点。只有在所有这些操作完成后,系统才会向名称节点反馈信息,通知它数据块已经存储。
同时,HDFS不支持为确保数据一致性而修改数据块。如果文件需要修改,唯一的方法是先删除原始文件,然后写一个新文件。这种模式是HDFS并发性高的原因之一。
(2)HDFS数据读取过程(a)当需要读取文件时,系统将首先向名称节点发送数据读取请求。
因为名称节点的存储器存储所有文件的元数据,包括对应于每个文件块的数据节点的物理位置。当名称节点收到系统的文件访问请求时,它将向系统返回与文件对应的所有数据节点的位置。
(三)系统从名称节点获取所有相关数据节点的地址后,根据地址将数据读入相应的数据节点。
除了在文件读取中提供数据节点的地址之外,名称节点实际上不参与文件读取。换句话说,文件不通过名称节点,而是直接在数据节点和客户端之间进行交互,文件直接从数据节点传输到客户端。这种模式极大地提高了HDFS读取文件的效率,使其在处理并发请求时非常高效。
客户端通过名称节点返回的一系列数据节点地址将数据读取到相应的数据节点。
读取文件时,HDFS客户端直接与数据节点交互,而名称节点仅处理地址,不提供数据服务。因为数据仅在数据节点之间流动,所以HDFS可以同时处理大量并发读取文件请求。
2.4本章摘要
为了深入了解云存储问题,本章对云存储相关技术进行了研究。这些包括云计算相关概念、分类和核心虚拟化技术。其次,研究了云存储系统的相关概念、应用分类和系统架构。最后,详细探讨了云存储的核心部分分布式文件系统。以HDFS为典型案例,分析了其相关组件和逻辑架构,研究了其读写文件的过程。通过以上相关技术研究,我们对云存储的实现模式有了更好的理解,并为接下来的章节奠定了坚实的基础。


