系统环境搭建和内存配置分析,编写程序通常需要什么样的计算机配置?
系统环境搭建和内存配置分析
编写程序通常需要什么样的计算机配置?这取决于您正在编写的程序和运行的开发环境。如果您正在运行一个数据库,如数据库服务器,建议您拥有大内存。如果您想要一个高速的中央处理器来运行虚拟机,如VMWare,内存大,中央处理器不能差,硬盘空间必须大,旋转速度必须快。如果你想运行一个安卓仿真开发环境,建议你的中央处理器要快,内存要大,要硬
visual studio 2015 对电脑配置有什么要求啊,比如...
官方说明如下:硬件要求1.6千兆赫或更快的1 GB内存(如果在虚拟机上运行,则为1.5 GB)处理器、20 GB可用硬盘空间5400转/分硬盘驱动器、DirectX 9兼容显卡,其显示分辨率为1024 x 768或更高的操作系统:视窗8.1(x86和x6,我在一家网络公司设计,参照我公司员工的计算机配置, 建议程序员和架构师仅配置通用办公计算机(单核和双核都可以,内存为1G,精英主板,硬盘配备通用尺寸)。 设计要求更高,因为设计软件正在运行。特别是在制作相对较大的文件时,根据微软的官方推荐,win7的最低配置要求如下:处理器:1 GHz 32位或64位处理器内存:1 GB或更多显卡:支持DirectX 9 128M或更多(开启AERO effect)硬盘空间:16G或更多(主分区,NTFS格式)显示:要求分辨率为1024X768像素或更多(低于此分辨率,内存不足异常的根本原因可能是您的程序有内存泄漏。配置大内存不是解决方案。如果有泄漏,即使配置为16G,也会发生错误。建议您下载。NET内存分析器来检查哪些泄漏Java-xmx 3550M-xms 3550m-xmn 2g-XSS 128k-xmx 3550m:将JVM的最大可用内存设置为3550m -Xms3550m:将JVM设置为内存3550m 该值可以设置为-Xmx,以避免JVM在每次垃圾收集完成后重新分配内存 -Xmn2G:将年轻一代的规模设置为2G 总堆大小=年轻一代,
编写程序通常需要什么样的计算机配置?
编写程序通常需要什么样的计算机配置?这取决于您正在编写的程序和运行的开发环境。如果您正在运行一个数据库,如数据库服务器,建议您拥有大内存。如果您想要一个高速的中央处理器来运行虚拟机,如VMWare,内存大,中央处理器不能差,硬盘空间必须大,旋转速度必须快。如果你想运行一个安卓仿真开发环境,建议你的中央处理器要快,内存要大,要硬
visual studio 2015 对电脑配置有什么要求啊,比如...
系统环境搭建和内存配置分析范文
本文的目录导航:
[标题]讨论码头工艺的Hadoop性能优化方法??
[第1章]码头工艺Hadoop性能优化研究简介
[第二章]码头工人技术相关知识背景介绍
[3.1-3.2]系统环境构建和内存配置分析
[3.3-3.5]基于码头集装箱的Hadoop架构平台构建
[第五章]纱线性能优化研究
[第6章]异构系统中的数据安全
[第7章]码头工艺中Hadoop性能的优化结论和参考
第三章系统环境构建和内存配置分析
为了分析Hadoop的性能,本文构建了一个基于Docker容器的Hadoop测试平台。本章首先介绍了构建系统所需的软件环境和硬件环境,然后描述了如何在Docker容器中构建Hadoop分布式平台。然后,通过对比实验分析了合适的内存分配参数,为异构环境下的数据安全研究奠定了基础。
3.1[系统环境大楼/S2/]
3.1.1硬件环境
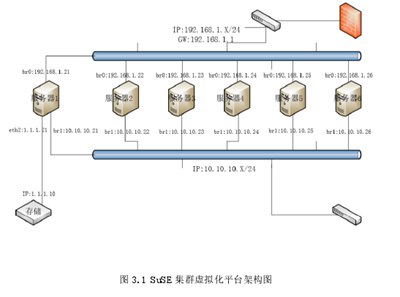
本实验基于实验室SuSE集群虚拟化平台。
SuSE集群虚拟化平台的架构图如图3.1所示,硬件配置如表3.1所示。

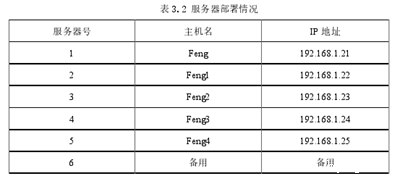
服务器的具体配置参数如表3.2所示。
防火墙配置:默认管理员冯;密码:
Admin/Admin @ 123;可以通过管理端口;管理站点知识产权为192.168.0.1,出口知识产权为10.10.21.123,接口为GE0/0/0。
本实验从曙光天阔I620-G10服务器中选取5台服务器,其余服务器作为备份。
五个服务器中的一个是主机名为feng的主节点,另外四个服务器分别是名为feng1、feng2、feng3和feng4的从节点。
3.1.2软件环境
基于Docker容器技术的整个Hadoop平台架构构建过程中所需的软件开发工具如下表3.3所示:

3.2系统方案的实施
3 . 2 . 1[集装箱集群建设/S2/]
首先,在实验室的五个服务器上,通过使用Dockerpull命令,Docker被下载、解压缩并安装在DockerHub中。为了便于在每台服务器上管理Docker容器集群,使容器集群的调度更加高效,以及便于Docker容器之间的跨服务器通信,本文的方案采用了库本内斯-谷歌开发的大型容器集群管理工具。将每个子服务器上的Docker容器部署到主服务器上的kubectl。实现代码如下:

3.2.2Hadoop平台构建流程
Hadoop分布式集群由1个主节点和4个从节点组成,它们通过Docker的openvswitch部署。主服务器中Docker容器中的Kubernetes集群架构更高效地完成容器之间的管理、自动更新、调度等功能。
通过Docker容器构建Hadoop平台架构的过程一般可以分为四个步骤:(1)通过Dockerfile下载、解压缩和安装Hadoop的基本映像。(2)配置SSH→JDK安装并配置环境变量。(3)配置Hadoop分布式相关文件。(4)Hadoop图像构建。
安全外壳(Secure Shell),一种安全外壳协议,主要是应用层的安全协议(传输层也可以扩展)。ftp和telnet等传输协议存在一些安全风险。例如,当纯文本未加密传输时,它可能会从中间被“截断”。宋承宪可以解决这个问题。SSH具有良好的压缩和加密功能,数据传输具有良好的保密性和快速性。因此,SSH被广泛应用于网络传输。
本实验使用SSH无密码登录,因为Hadoop部署在Docker容器中,所以有必要确保对容器的无密码访问和对Hadoop的无密码访问。最后,必须配置ApacheTomcat并完成hadoop-env.sh、core-site.xml、hdfs-site.xml、thread-site . XML、mapred-site.xml和其他配置文件的部署。
(1)核心站点. xml是配置HDFS(Hadoop分布式文件系统)的关键。在这种情况下,端口号和地址需要匹配。


(2)hadoop-env.sh可以配置hadoop的环境变量。

(3)纱线站点的作用。XML配置是确保Hadoop性能的一个重要因素,同时它还可以为浏览器提供查看集群部署的权限。

(4)HDFS站点的配置。xml是负责修改HDFS的备份方法。

(5)映射站点. xml配置用于为映射/减少并行化和分布式算法提供重要的权限。

3 . 2 . 3 locker集群部署方案
因为Hadoop平台是一个大规模分布式集群平台,所以Docker在处理大规模数据时必须启动许多容器来获得容器的镜像。为了更简洁高效地管理和调用Docker容器集群,该方案需要一个大规模的容器集群管理体系结构——库本内斯(Kubernetes)。
Kubernetes的内部架构源自Borg,这是谷歌集团(GoogleGroup)内部的一个大型集群管理工具。
Kubernetes不仅继承了Borg功能系统,还在主机之间部署、管理和应用容器。
因此,库本内斯的设计理念是为开发人员和用户提供简单方便的容器集群操作。这样,它建立了一个负载平衡框架机制,集成了容器的自动存储、备份、调度和重启。
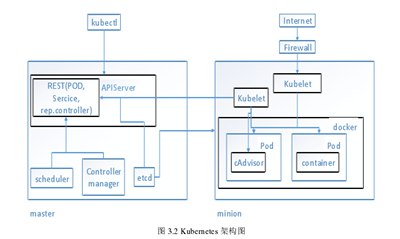
库伯内斯的工作原理如图3.2所示。左块和右块代表Kubernetes的两个重要节点:负载管理用户和资源管理节点-主节点。迷你节点负责集装箱运行监控。
主节点主要由两个组件组成,Rest和APIServer。
Rest负责资源调度和用户管理。具体来说,它是资源对象的接口。调度程序通过一系列调度算法调用Rest接口来控制和管理容器。
Kubernetes控制器管理器依靠主节点上运行的集群来更新和控制服务节点。
APIServer负责响应迷你节点中用户的请求。在KubernetesAPIService中,添加、删除、检查和修改任何节点的消息必须在响应请求后发送到后台存储等。
迷你节点可以分为两个主要部分:
ku blet和pod.clusters中所有码头集装箱的维护由ku blet组件完成。在库博莱,库博莱服务器进程负责存储所有码头集装箱的所有信息,然后将其反馈给Pod中的集装箱管理程序(ContainerAdvisor)。
豆荚不仅是奴隶主节点的重要组成部分,也是库伯内斯的灵魂。
豆荚就像一个容器。所有的容器都像货物一样包装在容器中。
当用户执行大规模容器调度时,容器就像一个容器和内部货物(容器),从一个主机服务器(主机)到另一个主机服务器。因此,它是Kubernetes容器集群部署管理的最小单元。
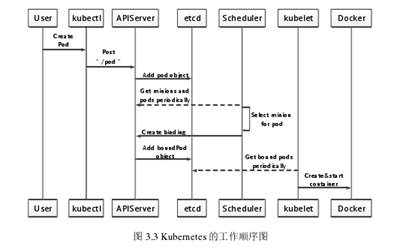
如图3.3所示,这是库本内斯核心组件工作的序列图。当用户向Kubernetes发送容器集群请求管理时,Pod首先被创建,然后kubectl向APIServer中的“/pod”节点发送post请求,以提供源容器配置文件。在应用编程接口验证库贝尔的成功请求后,它将执行一系列基本的源文件配置任务,并添加或创建一个用于调度后台工具(etcd)的pod接口。然后,在调度器将创建的pod接口绑定到etcd的后台管理架构之后,它可以执行kubelet的资源管理、调度、操作和同步更新。
Kubelet存储Docker容器的向量,因此当kubelet被调度时,kubelet向DockerAPI发送容器创建或打开请求。大多数码头集装箱集群也实现资源管理和调度。可以看出,这个Docker容器的资源调度过程可以看作是ectd的资源调度过程。
综上所述,为了解决大型Docker容器集群的部署、调度、更新和管理效率、健壮性等问题,本文提出了构建Docker集群的完整解决方案,即Kubernetes管理Docker容器,在Docker容器中部署、提取和创建Hadoop映像。这就形成了一个完整的基于Docker容器技术的Hadoop平台。


