基于卷积神经网络的视频目标定位检测,在卷积神经网络中,为什么验证分类精度高于测试精度
基于卷积神经网络的视频目标定位检测
在卷积神经网络中,为什么验证分类精度高于测试精度卷积神经网络有以下应用研究:1 .基于卷积网络的物体形状识别是人类视觉系统分析和识别物体的基础,几何形状是物体本质特征的表达,具有平移、缩放和旋转不变性等特点。,所以在模式识别领域,形状分析和识别是非常重要的
卷积神经网络可以用于小目标检测吗
当然,但是很难。作者:杨盛宴链接:来源:智湖版权归作者所有。请联系作者以获得转载授权。 “深度学习”(Deep learning)是一系列新的结构和新的方法,这些结构和新的方法是为了使具有更多层的多层神经网络能够被训练和工作。 在新的网络结构中最著名的是有线电视新闻网,它解决了传统更深层次网络的问题。看看你的目的是什么。一般来说,传统分类的输出是图片的类型,它也是你所说的一维向量,前提是你的输入图像也是一维标签。 如果输入矩阵的标签,也可以通过调整网络内核来输出矩阵的标签。 卷积神经网络具有以下研究应用:1 .基于卷积网络的物体形状识别是人类视觉系统分析和识别物体的基础。几何形状是物体本质特征的表达,具有平移、缩放和旋转不变性。因此,在模式识别领域,形状分析和识别是非常重要的。卷积神经网络是多层神经网络,每层由多个二维平面组成,每个平面由多个独立的神经元组成 图:卷积神经网络的概念演示:输入图像用三个可训练滤波器和一个加性偏差进行卷积。过滤过程如图1所示。卷积后,在C1层生成三个特征图。然后,特征,
在卷积神经网络中,为什么验证分类精度高于测试精度
在卷积神经网络中,为什么验证分类精度高于测试精度卷积神经网络有以下应用研究:1 .基于卷积网络的物体形状识别是人类视觉系统分析和识别物体的基础,几何形状是物体本质特征的表达,具有平移、缩放和旋转不变性等特点。,所以在模式识别领域,形状分析和识别是非常重要的
卷积神经网络可以用于小目标检测吗
基于卷积神经网络的视频目标定位检测范文
本文的目录导航:
面向深度学习的目标检测和搜索算法研究??
[第一章]基于深度学习的视频运动目标介绍
[第二章]学习视频运动目标的相关工作
[第三章]基于卷积神经网络的视频目标定位与检测
[第四章]基于时间空双流的视频角色运动检测
[第五章]基于循环神经网络的视频目标自然语言搜索
[第6章]目标检测和搜索算法的结论和参考文献
第三章基于卷积神经网络的视频目标定位检测
第二章,神经网络广泛应用于目标检测领域。无论使用什么方法,都必须提取初始候选边界。随着该方法的不断改进,原候选边界提取方法中的冗余问题得到了解决,目标检测的准确性和速度得到了很大提高。然而,检测位置的准确性被忽略了。候选边界只能粗略地表示目标的近似位置,即使通过回归算法微调边界位置也不能获得足够精确的位置。为了解决上述问题,本章提出了一种基于卷积神经网络的视频目标位置检测算法。
3.1问题描述
目前,目标物体检测与识别已成为计算机视觉领域的研究热点。对于给定的图片或视频帧,需要能够识别图片或视频帧中每个目标对象的类别以及目标对象在图片中的位置。在大多数目标物体检测方法中,矩形边界被用作目标物体的边界。目前,有几种常见的检测算法。一种是使用滑动窗口作为输入候选帧生成方法的传统目标检测方法。时间复杂度过高,冗余窗口过多,严重影响后续分类性能。为了解决这一问题,提出了另一种基于区域提议的深度学习检测方法,该方法在减小候选窗口的同时仍能保持较高的召回率。之后,为了在速度上取得进展,提出了一种类似于YOLO的方法。这种方法使用回归思想。对于给定的图片或视频帧,该位置的目标边界和目标类别直接回归到图片或视频帧的多个位置。
随着目标检测技术的发展,检测的准确性和性能逐渐提高。然而,这些方法的目标定位精度并没有得到提高。近年来,提高目标检测边界定位精度的要求也逐步提出。边界定位精度通过检测到的边界框和地面真实框的并集上的交集来测量。对于重叠率Io U小于0.5的检测边界,检测失败。包围盒回归范式是目标检测流水线的一部分,用于微调失败边界,提高定位精度。然而,仍然难以通过回归精确定位目标的边界框。
因此,在现有目标检测流水线的基础上,提出了一种基于卷积神经网络的目标边界概率模型定位算法,取代了目标检测流水线中的边界框架回归算法,最终训练神经网络完成目标的高定位精度检测。
基于边界盒概率[的3.2卷积神经网络定位模型/s2/]
第二章介绍卷积神经网络的结构原理和应用。本章将使用卷积神经网络来定位和检测目标。其中,定位模型是整个目标检测过程的重点。本章将从边界概率预测原理、边界概率表示方法和基于卷积神经网络的模型结构三个方面详细描述定位模型。
3.2.1边界盒概率预测原理
本章考虑构造卷积神经网络学习任务,通过回归函数直接获得检测目标边界的位置坐标。然而,实验证明很难构建这样的学习任务,并且不能生成精确的边界。因此,我们提出了行或列上的概率模型,并通过行或列上的概率来确定边界框的位置。
边界概率预测模型的一般工作流程如下:对于给定的图片和图片的候选帧b,将候选帧b扩展固定倍数,得到搜索区域r,将固定参数设置为t=2,然后根据搜索区域r中每行和每列为一帧的概率或帧中的概率,得到定位比候选帧b更精确的帧。

图3.1粗略地示出了这样的工作流程,其中黄色帧表示原始候选帧b,红色帧表示搜索区域r,蓝色帧表示新获得的候选帧。
3.2.2边界盒概率表示
下面将详细描述表示边界概率的方法。对于给定的搜索区域r和类型c的目标检测


通过最大化()2Loc B,可以确定第二概率表示方法下新边界框的坐标值。
3.2.3基于深度卷积神经网络的定位模型框架采用
本章提出的基于深度卷积神经网络的定位模型锁定有线电视新闻网框架图如图3.2所示。该模型的设计首先通过深度卷积神经网络提取图像的底部特征。然后,汇集搜索区域的特征图,通过卷积层的卷积获得位置感知特征图。最后,通过汇集获得行和列的特征码。定位模型框架将在以下段落中详细阐述。




3.3视频目标定位检测算法流程设计
本章提出的视频目标位置检测算法框架包括两个基本部分,即目标识别模型和目标位置模型。在本节提出的算法流程中,辨识模型和定位模型采用迭代方法融合。

 [38]
[38]
 [39]
[39]
3.4实验和结果分析
3.4.1实验设计
本章使用的数据集是PASCAL VOC数据集,它为图像目标检测提供了一套标准化的优秀数据。数据集的训练集由一系列图片组成,每张图片都标有目标的边界框和目标的类别。本章中的识别模型和定位模型将以VOC2007和VOC2012中的训练数据作为本实验的训练集,以VOC2012中的训练数据作为本实验的测试集。
本章中的实验主要分为两步进行一次迭代。第一步是通过识别模型完成视频帧中的目标检测。本章使用的Girshick提出的Fast-RCNN模型完成了视频帧目标的识别,在视频帧中输入视频帧和目标候选边界,利用选择性搜索和边缘盒(Edge Box)两种候选边界算法方法提取初始候选边界,输出视频帧目标的候选边界和视频目标对应类别的置信度。在第二步骤中,在前一步骤中获得的检测目标的候选边界被输入到定位模型中,并且输出新的候选边界以获得更好的目标检测位置。定位模型是本章的核心,下面将详细描述定位模型的实验细节。
首先对识别模型得到的目标检测候选帧进行预处理,剔除与人工标记帧重叠率Io U值小于0.4的候选帧,删除定位不良的候选帧,将剩余的候选帧扩展2的固定参数t=2,得到搜索区域r。定位模型输入预处理得到的结果,最后得到某一行或某一列的边界概率。通过获得的概率,最终可以确定定位更准确的候选边界。在定位过程中,检测目标的类型与检测目标的类型无关,检测目标的类型不会影响最终的定位结果。参数M的值控制分支x和y的最终输出特性图的概率,并且被设置为M=14。为了优化训练过程中的稳定性和收敛速度,所使用的随机梯度下降方法SGD(股票梯度下降)的相关参数被调整为[42],小批量的大小被设置为128,并且每个批量的128个候选帧仅从两个不同的图片中获取。权重衰减参数设置为0.00005,学习率设置为0.001,每60次迭代将减少到原来的10次。整个训练过程将持续15万次迭代。
3.4.2结果分析
本章的实验将分析评价标准的结果和结果的比较。
(1)评价标准在本节中,实验结果是通过对三个定量指标的分析得出的:召回率、平均召回率ar和准确率mapp(平均平均平均准确率)。召回率(Recall rate)是指检索到的相关目标候选边界框与所有候选边界框的比率,用于衡量本节边界框定位的优缺点。平均召回率AR指召回率召回率和重叠率U0曲线和坐标轴的面积,取值范围[]0,1。平均精度表示精度和召回率召回曲线和坐标轴的面积,取值范围为[]0。1.精度指数m AP(平均精度)是指对应于多个类别的平均精度AP(平均精度)的平均值,范围为[]0,1。
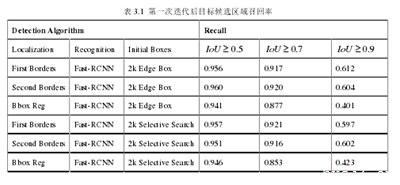
(2)结果比较(Results Comparison)首先,本章提出的目标检测流水线中的定位模型与传统的边界回归定位模型的比较将忽略目标识别模型的性能评价,召回率将作为衡量定位质量的评价标准。为此,相同的识别模型Fast-RCNN和相同的列候选帧将被用作定位模型的输入。此时,输出候选帧的召回率反映了定位模型的定位性能。表3.1显示了不同定位模型下目标检测流水线第一次迭代后,输出候选边界的召回率随重叠率阈值Io U的变化曲线。可以得出结论,对于Io U阈值大于0.7的候选边界,本章提出的定位模型获得的召回率大于包围盒回归模型获得的召回率,并且随着Io U阈值的增加,召回率的提高更加明显。对于平均召回率AR(average recall),本章提出的模型获得的值平均比边界盒回归模型获得的值高6个百分点。
然后,对整个改进的目标检测流水线的目标识别性能进行分析。图3.2中的结果是在整个目标检测过程的T=4次迭代之后获得的实验结果。图表显示了在测试集VOC2007上,当Io U阈值分别大于0.5和0.7时,目标检测的多类别平均精度。根据观测表,对于重叠率Io U值大于0.7的候选边界,本章提出的第一边界概率定位模型和第二边界概率定位模型可以在一定程度上提高整个目标检测流水线的识别精度,优于边界框架回归定位模型。对于重叠率Io U值大于0.5的候选边界,只提供了一点点优化。还可以得出结论,本章提出的改进目标检测流水线对边界框提取方法不敏感。

3.5本章摘要[/s2/]
本章在深入研究的基础上对目标检测技术进行了深入的研究和探索,提出了一种基于深度卷积神经网络的高精度定位目标检测流水线。管道主要通过迭代将识别模型与定位模型相结合。在迭代过程中,提高了定位和目标识别的精度。在目标检测流水线中,最重要的部分是定位模型。在接下来的章节中,详细描述了定位模型的工作原理。本地化模型主要分为三个部分。第一部分通过深度卷积神经网络VGG初步提取图像特征,第二部分通过两层卷积神经网络提取前一特征图中搜索区域R的特征,得到搜索区域R的新特征图像,第三部分将模型分为两个分支,两个分支分别通过这两个分支得到二维方向上的边界盒概率向量。最后,通过概率向量可以获得更精确的边界。最后,在实验部分,以召回率和准确率为评价标准,对目标检测水线进行了验证。
实验结果表明,利用本章提出的定位模型进行目标检测比利用包围盒回归模型进行目标检测具有更高的召回率和识别精度。这表明本章提出的定位模型能够更准确地定位和识别视频帧中的目标。
然而,该模型仍有许多缺点,需要改进。例如,当视频帧中存在多目标对象[43]时,识别目标太小[44]并且由于天气[45],视频帧是模糊的,这些问题没有被充分考虑。如果这些问题能够得到成功解决,目标检测能力将得到客观的提高,我将继续研究视频中的目标运动识别。


